
具身智能篇---VLA(Vision-Language-Action)
VLA模型是具身智能领域的突破性技术,通过端到端多模态架构实现视觉、语言到动作的直接映射。它将机器人动作离散化为Token,采用Transformer架构融合视觉和语言信息,具备零样本泛化和常识推理能力。代表性模型如RT-2、Octo等展示了语义泛化和多任务统一优势,但仍面临推理延迟、数据需求和安全挑战。未来将向多模态扩展、结合世界模型、优化效率等方向发展,是实现通用机器人的核心技术路径。
·
VLA (Vision-Language-Action) 模型 是具身智能(Embodied AI)领域的“圣杯”,被视为让机器人从“执行预设程序的机器”进化为“能理解世界并自主行动的通用智能体”的关键技术突破。
简单来说,VLA 模型是一个端到端(End-to-End)的多模态大模型,它直接将视觉输入(看到了什么)和语言指令(要做什么)映射为物理动作(怎么做),跳过了传统机器人学中复杂的中间编程环节。
一、VLA 模型的核心概念深度解析
1. 定义与范式转变
- 传统机器人栈:感知(CV模型) →→ 语义理解(NLP模型) →→ 任务规划(符号逻辑/代码) →→ 轨迹生成(控制算法) →→ 执行。
- 缺点:模块间误差累积,泛化能力差,难以处理未见过的物体或指令。
- VLA 模型栈:
[图像 + 文本]→VLA ModelVLA Model[动作 Token / 关节扭矩]。- 优点:端到端学习。模型通过海量数据直接学习“看到A,听到B,就做C”的映射关系,具备极强的零样本(Zero-shot)泛化能力。
2. 核心架构原理
VLA 模型通常基于 Transformer 架构演进而来,其核心创新在于将“动作”视为一种特殊的“语言”。
- 多模态编码器 (Multimodal Encoder):
- 视觉:使用 ViT (Vision Transformer) 将摄像头图像切分为 Patch,编码为视觉 Token。
- 语言:使用 LLM (如 PaLM, Llama) 的 tokenizer 将指令编码为文本 Token。
- 融合:通过交叉注意力机制(Cross-Attention)将视觉和文本信息对齐融合。
- 动作分词化 (Action Tokenization):
- 这是 VLA 的灵魂。连续的机器人动作(如关节角度、速度、夹爪开合度)被离散化为Token。
- 方法:通常使用标量量化(Scalar Quantization)或向量量化(VQ-VAE)。例如,将关节角度 0.50.5 rad 映射为 token ID
1234。 - 结果:动作预测变成了像预测下一个单词一样的自回归(Autoregressive)生成任务。
- 预训练与微调:
- 基座模型:通常在互联网规模的图文数据上预训练(获得通用常识)。
- 机器人微调:在大规模的机器人操作数据集(如 Open X-Embodiment,包含数百万条演示轨迹)上进行微调,学习物理世界的因果律。
3. 代表性模型 (截至2026年)
- RT-2 (Robotic Transformer 2):Google DeepMind 的里程碑作品。它证明了 VLA 模型不仅能控制机器人,还能涌现出推理能力(例如:看到“可乐”,指令“给我喝的”,它能推理出可乐是可以喝的,并去抓取,即使训练数据中没有明确写过“可乐是饮料”)。
- Octo:伯克利推出的开源通用策略模型,展示了在多种不同形态机器人上的迁移能力。
- OpenVLA:社区驱动的开源基座,降低了 VLA 的训练门槛,支持快速适配新机器人。
- Figure 01 / Tesla Optimus 内部模型:商业落地的 VLA 变体,结合了世界模型,实现了更流畅的长程操作。
4. 关键优势
- 语义泛化:能理解抽象指令(如“把那个看起来容易碎的东西轻点放”),而不仅仅是坐标指令。
- 开放词汇操作:能识别并操作训练集中从未出现过的物体(只要它认识这个物体的概念)。
- 多任务统一:同一个模型可以完成抓取、导航、折叠衣物等完全不同的任务,无需切换算法。
- 常识推理:继承了大语言模型的常识,能处理隐含意图。
5. 面临的挑战
- 推理延迟:自回归生成动作序列较慢(通常 5-10Hz),难以满足高频控制(1kHz)需求。
- 解决方案:采用扩散策略 (Diffusion Policy) 替代自回归,或使用动作块 (Action Chunking) 一次预测未来多步动作。
- 数据饥渴:需要海量的高质量机器人交互数据,采集成本极高。
- 安全性:黑盒模型可能产生幻觉,导致危险动作,需要安全层(Safety Layer)兜底。
二、VLA 模型的工作流程
- 输入阶段:
- 机器人摄像头捕捉当前场景图像 ItIt 。
- 用户输入语音或文本指令 LL (如“把苹果放进篮子”)。
- (可选)历史动作序列 At−k:tAt−k:t 作为上下文。
- 编码与融合:
- 视觉编码器提取图像特征。
- 语言编码器提取指令特征。
- Transformer 主干网络融合特征,理解“在当前画面中,哪个是苹果,哪个是篮子,以及如何移动手臂”。
- 动作生成:
- 模型以自回归方式或扩散方式,预测接下来的动作 Token 序列。
- 输出可能是:
[左臂x+, 右臂y-, 夹爪open, ...]。
- 解码与执行:
- 将 Action Token 反量化为具体的电机控制信号(位置、速度、扭矩)。
- 底层控制器执行动作。
- 闭环反馈:
- 环境状态改变,摄像头捕捉新图像 It+1It+1 ,进入下一轮推理。
三、Mermaid 总结框图
以下图表展示了 VLA 模型的内部数据流向、架构组件以及与机器人系统的交互闭环:
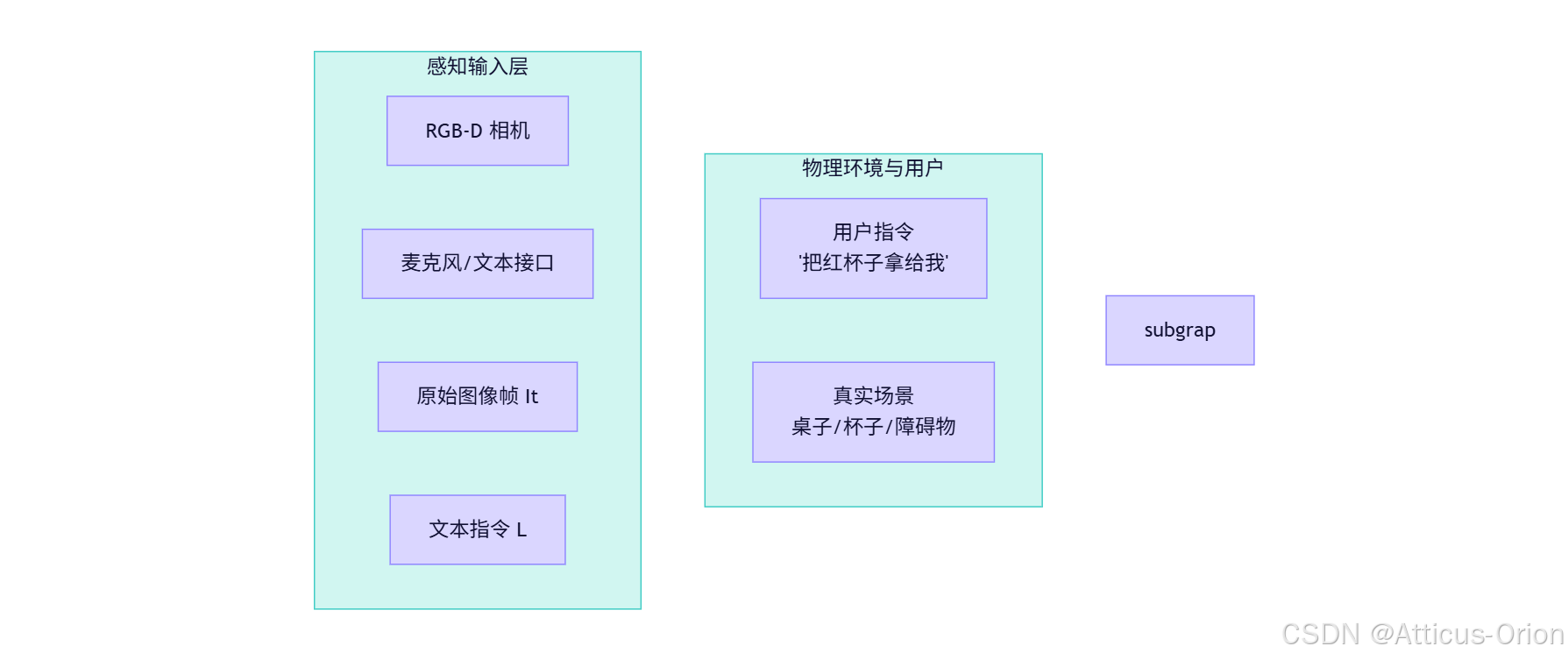
四、VLA 模型的未来演进方向 (2026+)
- 多模态输入的扩展:
- 不仅限于视觉和语言,还将融入触觉(Tactile)、听觉(Audio)甚至热成像数据,形成真正的“全感官”VLA。
- 与世界模型的结合:
- 单纯的 VLA 是反应式的。未来将结合世界模型(World Model),让机器人在生成动作前,先在内部模拟推演后果(“如果我这样抓,杯子会碎吗?”),实现思维链(Chain of Thought)规划。
- 效率优化:
- 通过模型蒸馏、量化和专用 NPU 架构,将 VLA 的推理延迟从几百毫秒降低到几十毫秒,使其能胜任高速动态任务(如接球、避障)。
- 终身学习 (Lifelong Learning):
- 机器人不再是一次性训练完成,而是能在部署后,通过人类的少量纠正或自主探索,持续更新 VLA 模型的权重,适应新环境和新任务。
总结:VLA 模型是具身智能的“大脑皮层”,它将机器人的感知、认知和行动统一在一个概率模型中,是实现通用机器人(General Purpose Robots)最核心的技术路径。
更多推荐
 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)