
具身智能控制: MPC、WBC与RL的融合与发展
仿人机器人与具身智能控制技术综述 仿人机器人结合AI、计算机视觉等技术实现自然交互,但运动控制仍面临挑战。具身智能强调通过物理身体与环境互动发展智能,其核心特征包括身体性、情境性和自主性。双足机器人控制涉及动力学复杂性、步态切换、平衡维持等难题,需解决非线性耦合系统的高自由度控制问题。主流算法包括: 倒立摆+ZMP模型:简化质心动力学,通过零力矩点保持稳定,但步态受限; SLIP模型:模拟弹簧腿动
1. 仿人机器人与具身智能概述
仿人机器人是模拟人类行为和外貌的机器人,通过结合先进技术如人工智能、计算机视觉、语音识别和自然语言处理等,实现更真实的人机交互,满足人类对更复杂互动的需求。虽然目前市场上已有波士顿动力的Atlas、Agility Robotics的Digit以及Tesla的Optimus等较为成熟的产品,但有关仿人机器人运动控制的开源内容依旧有限。
具身智能(Embodied Intelligence)是指智能体通过与物理环境的交互而获得、发展和表达的智能形式。与传统人工智能不同,具身智能强调智能体必须拥有物理身体,能够感知环境并与之互动。这一概念源于认知科学和机器人学的交叉研究,挑战了传统人工智能中将思维视为纯粹符号处理的观点。
具身智能的核心特征
- 身体性: 智能体拥有物理实体,能够感知和操作物理世界
- 情境性: 智能体的行为受到当前环境情境的影响和约束
- 互动性: 智能能力通过与环境的持续互动而发展
- 自主性: 智能体能够独立决策并采取行动
- 适应性: 能够根据环境变化调整行为策略
在仿人机器人领域,具身智能控制系统的目标是使机器人能够像人类一样自然地行走、奔跑、跳跃,并完成各种复杂的操作任务。这要求控制系统能够精确控制机器人的每个关节,同时保持整体平衡和协调性。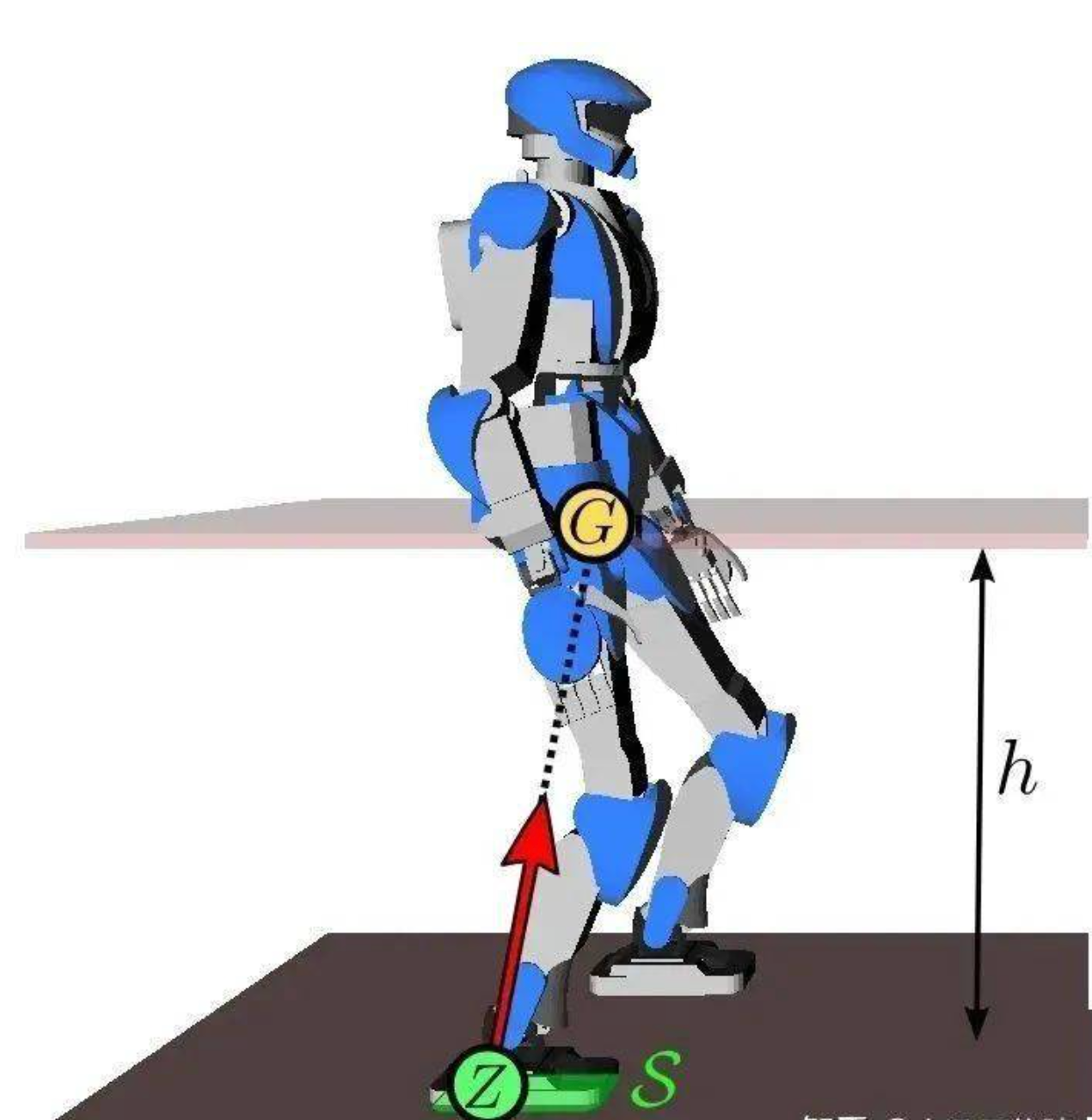
2. 双足机器人控制的基本挑战
双足机器人的控制具有很高的技术难度,尤其是步态控制和平衡问题。这种难度主要源于以下几个方面:
-
动力学复杂性
双足机器人是高度非线性、强耦合的动力系统。典型的人形机器人拥有30个以上的自由度,每个关节的运动都会影响整个系统的平衡和稳定性。此外,关节间的动力学耦合使得控制更加复杂。 -
支撑状态变化
双足机器人在行走过程中不断地在单支撑相(一只脚着地)和双支撑相(两只脚着地)之间切换,这种混合动力学特性使控制系统需要处理离散的状态转换。 -
接触动力学
机器人足部与地面的接触是一个复杂的物理过程,涉及到力的传递、摩擦和冲击。在不平整地面上行走时,这种接触关系变得更加复杂。 -
平衡控制
与轮式或履带式机器人不同,双足机器人需要主动维持平衡,这要求控制系统能够快速响应外部扰动和内部动力变化。 -
能量效率
人类行走是一个能量效率极高的过程,而大多数双足机器人的能耗远高于人类。如何设计能量效率高的步态是一个重要挑战。 -
鲁棒性和适应性
实际环境中存在各种不确定性,如地面条件变化、外部扰动等,控制系统需要具备足够的鲁棒性和适应性来应对这些变化。
在解决这些挑战的过程中,研究人员开发了多种控制算法,从早期的静态步态控制发展到现在的动态步态控制。接下来,我们将详细介绍几种主流的控制方法。
3. 双足机器人控制算法演变
3.1 倒立摆+ZMP模型
以日本为代表的倒立摆(Linear Inverted Pendulum, LIP)算法,结合零力矩点(Zero Moment Point, ZMP)在双足机器人步态上的应用最为经典。该方法由梶田秀司(Shuuji Kajita)在《人形机器人》一书中详细介绍。
3.1.1 理论基础
LIP模型将机器人简化为一个由质点和无质量支撑腿组成的倒立摆。在该模型中,假设质点沿水平面运动,质点高度保持不变。其动力学方程为:
x ¨ = g h ( x − p x ) \ddot{x} = \frac{g}{h}(x - p_x) x¨=hg(x−px)
其中, x x x是质点的水平位置, p x p_x px是ZMP的位置, g g g是重力加速度, h h h是质点高度。
ZMP定义为地面上的一点,在该点上,机器人所有关节产生的惯性力和重力的合力矩在水平面内为零。当ZMP位于支撑多边形内时,机器人保持稳定;当ZMP到达支撑多边形边缘时,机器人开始倾斜;当ZMP位于支撑多边形外时,机器人将失去平衡。
3.1.2 控制策略
基于LIP和ZMP的控制策略主要包括以下步骤:
- 规划参考ZMP轨迹,通常是在支撑多边形内移动的平滑轨迹
- 基于LIP动力学方程,求解质心轨迹
- 通过逆运动学计算各关节角度
- 实时监测实际ZMP位置,通过反馈控制调整质心位置
这种方法的优点是计算简单,理论基础扎实,但缺点是要求质心高度恒定,导致机器人只能采用屈膝行走姿态,能量效率低且不自然。
代表性机器人
- 本田的Asimo: 世界上第一个能够实现稳定双足行走的商用人形机器人
- 优必选的Walker: 集成了语音交互、面部识别等功能的服务型人形机器人
- 德国宇航局的TORO: 专注于研究人形机器人动力学和控制的平台
随着研究的深入,该方法也衍生出多种变体,如Divergent Component of Motion (DCM)算法,以及Kajita在2018年提出的基于Spatially Quantized Dynamics (SQD)的算法,后者能够实现更接近人类的直膝行走步态。
3.2 弹簧负载倒立摆模型(SLIP)
弹簧负载倒立摆模型(Spring-Loaded Inverted Pendulum, SLIP)由Marc Raibert在1986年的《Leged Robot that Balance》一书中提出。Raibert是MIT前教授,也是波士顿动力公司的创始人。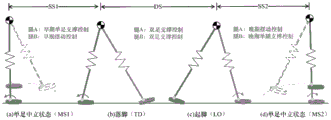
3.2.1 理论基础
SLIP模型将机器人简化为一个由质点和带弹簧的支撑腿组成的系统。在单腿跳跃机器人中,支撑腿被建模为一个无质量的弹簧,可以压缩和伸展。其动力学可以分为三个阶段:
- 飞行阶段:质点在重力作用下做抛物线运动
- 着地阶段:弹簧压缩,存储能量
- 离地阶段:弹簧释放能量,推动质点再次起飞
3.2.2 控制策略
Raibert提出的"三部独立控制法"(Three-Part Control)是SLIP控制的经典方法,它将控制问题解耦为三个相对独立的任务:
- 高度控制:通过调整弹簧的刚度或预压缩量来控制跳跃高度
- 前进速度控制:通过调整落脚点位置来控制水平速度
- 身体姿态控制:通过调整支撑腿和身体之间的力矩来控制身体姿态
其中,落脚点控制是关键,可以表示为:
x f o o t = x C o M + x ˙ C o M ⋅ k x_{foot} = x_{CoM} + \dot{x}_{CoM} \cdot k xfoot=xCoM+x˙CoM⋅k
其中 x f o o t x_{foot} xfoot是落脚点位置, x C o M x_{CoM} xCoM是质心位置, x ˙ C o M \dot{x}_{CoM} x˙CoM是质心速度, k k k是增益系数。
3.2.3 代表性工作
俄勒冈州立大学(OSU)的Jonathan W. Hurst团队在基于SLIP的动态步态方面做了大量研究,开发了ATRIAS和Cassie等机器人。Cassie采用鸵鸟腿设计,能够在不平地面上稳定行走。后来,Hurst创立了迅捷机器人公司(Agility Robotics),开发出了带上半身的Digit机器人,已经开始商业化应用。
SLIP模型的优点是能够捕捉动态行走和跑步的本质特性,能效较高,但难以处理复杂的多关节系统和三维运动。
3.3 Hybrid Zero Dynamics (HZD)
混合零动力学(Hybrid Zero Dynamics, HZD)方法是由密歇根大学的Jessy Grizzle团队开发的,这种方法在全身动力学模型上应用非线性控制理论。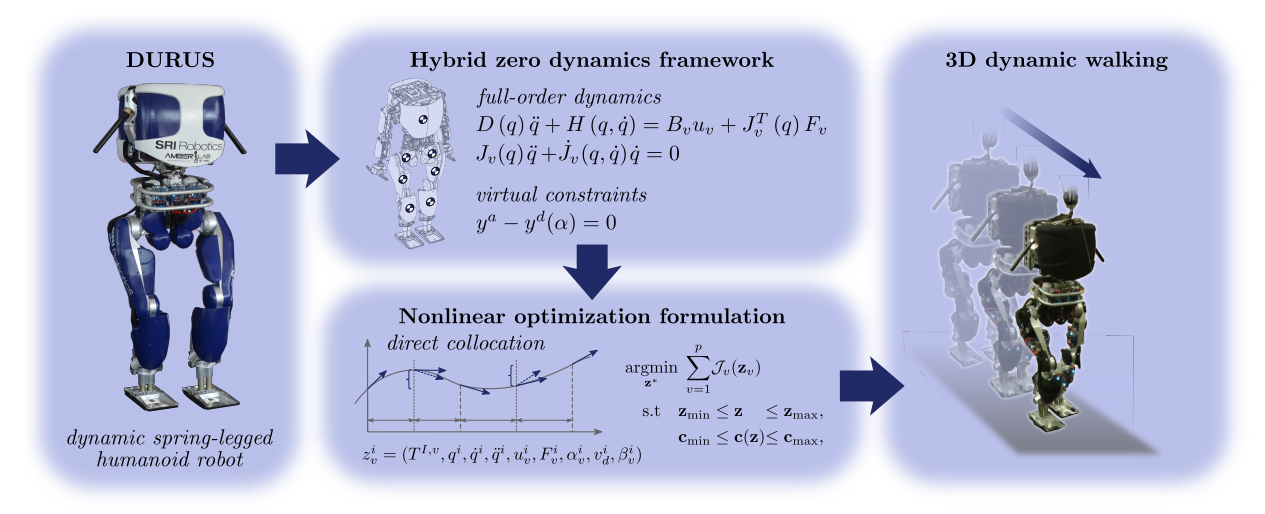
3.3.1 理论基础
HZD方法将双足行走视为混合动力系统,包含连续动力学阶段(单支撑)和离散状态跳变(足部着地)。其核心思想是通过定义一组输出函数(虚拟约束),将高维非线性系统约束到一个低维流形上,在这个流形上系统展现出稳定的周期性行为。
数学上,HZD可以表述为,定义输出函数:
y = h ( q ) − h d ( τ ( q ) ) y = h(q) - h_d(\tau(q)) y=h(q)−hd(τ(q))
其中 h ( q ) h(q) h(q)是实际输出, h d ( τ ( q ) ) h_d(\tau(q)) hd(τ(q))是期望输出, τ ( q ) \tau(q) τ(q)是相位变量。
设计反馈控制器使得 y → 0 y \to 0 y→0,即系统跟踪期望输出。
分析零动力学流形上的系统行为,确保周期稳定性。
3.3.2 控制策略
HZD控制策略主要包括以下步骤:
- 步态优化:使用轨迹优化方法生成满足动力学约束和稳定性要求的步态
- 构建步态库:为不同的速度、地形等情况生成不同的步态,形成步态库
- 在线控制:根据当前状态从步态库中选择合适的步态,通过输入输出线性化等方法跟踪参考轨迹
- 稳定性分析:使用Poincaré映射等工具分析闭环系统的稳定性
3.3.3 代表性工作:
HZD方法在MABEL、ATRIAS和Cassie等机器人上成功应用。近年来,Grizzle团队提出了基于角动量的速度和姿态调节方法,提高了机器人在不平地面上的适应性。
加州理工大学Amber Lab的Aaron Ames也大量应用HZD方法,并开发了轨迹优化软件包frost-dev,简化了HZD的应用。
HZD方法的优点是具有严格的稳定性保证,能够生成高效动态步态,但计算复杂度高,实时应用具有挑战性。
3.4 全身控制 (Whole Body Control, WBC)
全身控制(WBC)方法由德克萨斯大学奥斯汀分校的Luis Sentis开创,已成为DARPA机器人挑战赛的通用控制方法。
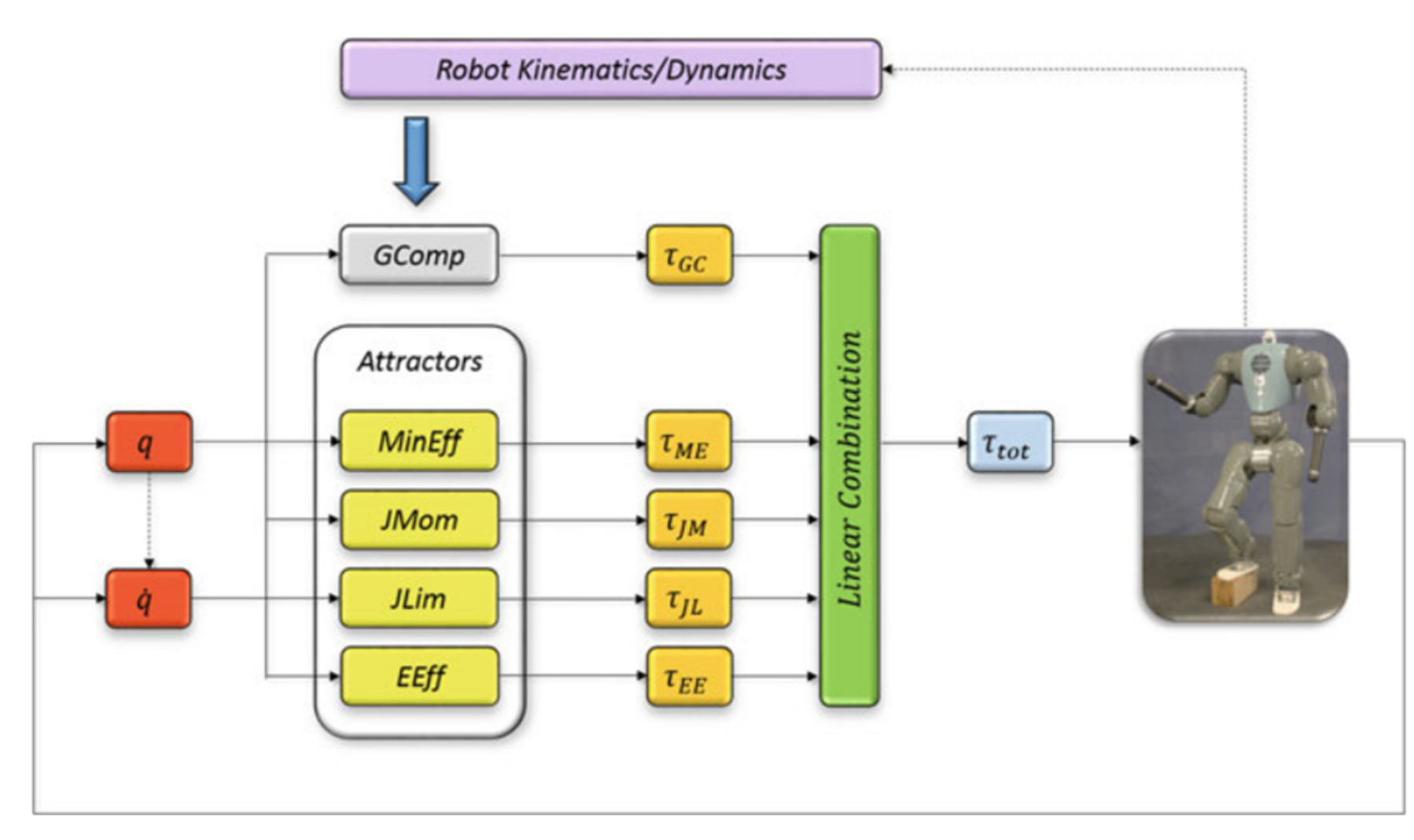
3.4.1 理论基础
WBC的核心思想是将机器人的多任务控制问题分解为具有不同优先级的子任务,并通过零空间投影方法确保高优先级任务不受低优先级任务的影响。其数学表述为:
τ = J 1 T F 1 + N 1 J 2 T F 2 + N 1 N 2 J 3 T F 3 + … \tau = J_1^T F_1 + N_1 J_2^T F_2 + N_1 N_2 J_3^T F_3 + \ldots τ=J1TF1+N1J2TF2+N1N2J3TF3+…
其中, τ \tau τ是关节力矩, J i J_i Ji是第 i i i个任务的雅可比矩阵, F i F_i Fi是任务空间力, N i N_i Ni是第 i i i个任务的零空间投影矩阵,定义为 N i = I − J i # J i N_i = I - J_i^{\#} J_i Ni=I−Ji#Ji,其中 J i # J_i^{\#} Ji#是 J i J_i Ji的伪逆。
3.4.2 控制架构
WBC控制架构通常分为两个模块:
- 基于运动学的WBC模块(KinWBC):将机器人行走分为双支撑、过渡和摆动阶段,根据不同阶段设定不同的任务优先级,计算期望的关节角度、角速度和角加速度。
- 基于动力学的WBC模块(DynWBC):接收KinWBC的输出,求解优化问题得到关节力矩。
常见的任务包括:
- 基础任务:浮基动力学方程,必须精确满足
- 高优先级任务:支撑足位置、身体姿态控制
- 中优先级任务:摆动足轨迹、手部位置控制
- 低优先级任务:姿态优化、关节极限避免等
3.4.3 代表性工作
Luis Sentis团队在Mercury机器人上验证了WBC方法的有效性,展示了其良好的动态稳定性和抗干扰能力。MIT的DONGHYUN KIM将WBC应用于Mini Cheetah四足机器人,使其速度达到3.7m/s。
WBC的优势在于能够统一处理多种约束和任务目标,适用于具有冗余自由度的复杂机器人系统,但计算复杂度高,需要精确的动力学模型。
3.5 模型预测控制 (Model Predictive Control, MPC)
模型预测控制(MPC)最初应用于化工过程控制和自动驾驶领域,近年来被广泛应用于足式机器人。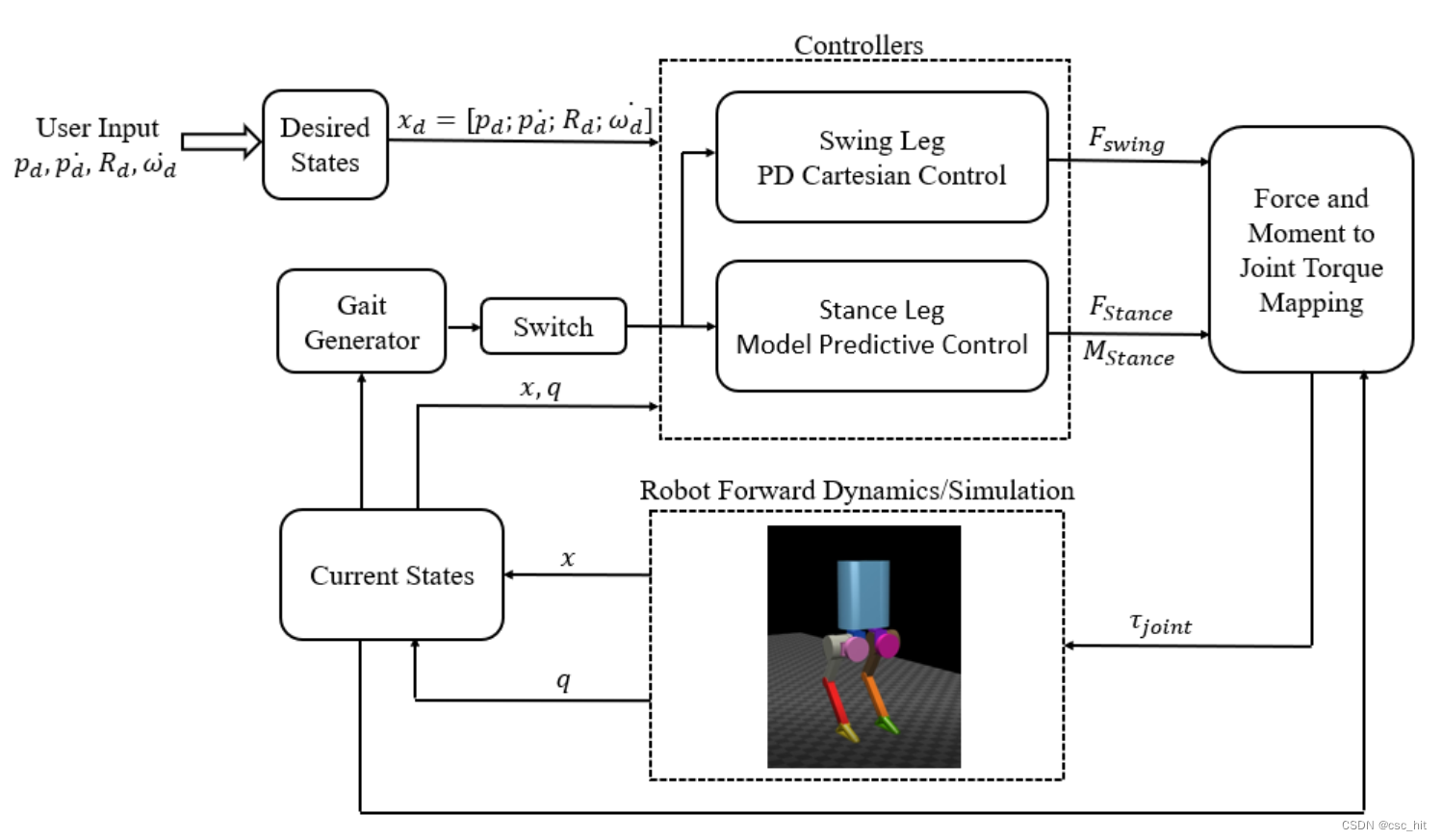
3.5.1 理论基础
MPC的核心思想是在滚动时域内求解一个有限时域最优控制问题。其基本步骤包括:
- 基于当前状态和控制模型预测未来一段时间内系统的行为
- 求解优化问题,找到使性能指标最优的控制序列
- 应用控制序列的第一个元素
- 在下一个时间步重复上述过程
对于双足机器人,MPC问题可以表述为:
min u 0 : N − 1 ∑ k = 0 N − 1 [ ∣ ∣ x k − x k r e f ∣ ∣ Q 2 + ∣ ∣ u k ∣ ∣ R 2 ] \min_{u_{0:N-1}} \sum_{k=0}^{N-1} \left[ ||x_k - x_{k}^{ref}||_Q^2 + ||u_k||_R^2 \right] u0:N−1mink=0∑N−1[∣∣xk−xkref∣∣Q2+∣∣uk∣∣R2]
x k + 1 = f ( x k , u k ) u k ∈ U , x k ∈ X \quad x_{k+1} = f(x_k, u_k) u_k \in \mathcal{U}, x_k \in \mathcal{X} xk+1=f(xk,uk)uk∈U,xk∈X
其中, x k x_k xk是系统状态, u k u_k uk是控制输入, x k r e f x_k^{ref} xkref是参考状态, Q Q Q和 R R R是权重矩阵, f f f是系统动力学模型, U \mathcal{U} U和 X \mathcal{X} X分别是控制和状态约束集。
3.5.2 控制策略
在双足机器人控制中,MPC通常采用简化的动力学模型,如质心动力学模型:
c ¨ = 1 m ∑ i f i + g \ddot{c} = \frac{1}{m} \sum_{i} f_i + g c¨=m1i∑fi+g
L ˙ = ∑ i ( p i − c ) × f i \dot{L} = \sum_{i} (p_i - c) \times f_i L˙=i∑(pi−c)×fi
其中, c c c是质心位置, m m m是总质量, f i f_i fi是第 i i i个接触点的力, g g g是重力加速度, L L L是角动量, p i p_i pi是接触点位置。
约束通常包括:
- 动力学约束
- 接触力约束(摩擦锥、单向约束)
- ZMP约束
- 足部轨迹约束
- 关节极限约束
3.5.3 代表性工作
MIT的Mini Cheetah四足机器人采用基于MPC的控制架构。波士顿动力公司的Atlas机器人在跑酷和舞蹈等复杂动作中也大量应用了MPC技术。根据波士顿动力团队负责人Scott Kuindersma的介绍,他们的算法框架分为离线和在线两部分:首先通过离线优化生成行为模板库,然后在线使用高速MPC跟踪相应的步态并实现动作切换。
优必选研究院和清华大学赵明国教授团队研究了基于力和力矩的MPC方法,以实现双足机器人的高动态运动,以及基于质心模型的MPC步态合成方法。
MPC的优势在于能够显式处理约束,预测未来行为,适应环境变化,但计算复杂度高,实时实现具有挑战性。
3.6 强化学习 (Reinforcement Learning, RL)
随着机器学习的兴起,强化学习越来越多地被应用于机器人控制,特别是在处理高维度问题时具有天然优势。当波士顿动力的Atlas机器人完成高难度后空翻,当特斯拉Optimus在工厂里稳健行走时,这些突破背后都离不开基于强化学习的步态训练。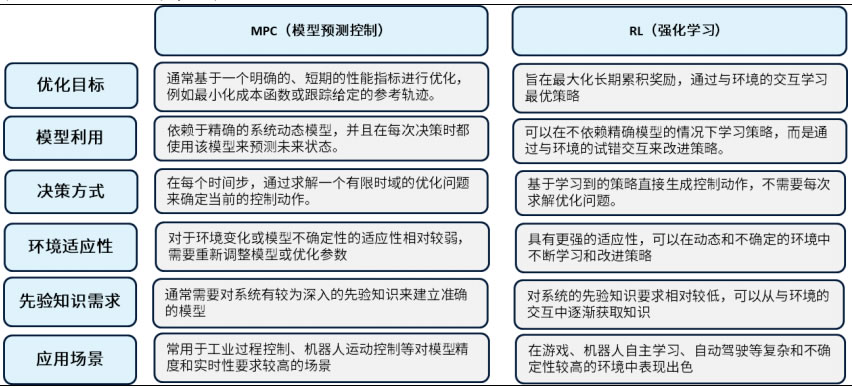
…详情请参照古月居
更多推荐

 28
28 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)