
具身智能hil-serl强化学习算法在lerobot机械臂上复现
原始文章发表在知乎,辛苦移步~最近把hil-serl在lerobot机械臂上跑了一下,网上也没找到其他同学的成功的复现分享,所以笔者一路过关斩将解决问题,在此记录一下,希望对大家也能有所帮助。hil-serl是2024年底的一篇文章,作者罗剑岚目前是智元的首席科学家。整体来看,其实hil-serl的思想挺简单的:传统在在线强化学习采样过程可能是算法驱动的,例如随机探索,这样效率比较低,训练时长会较
原始文章发表在知乎,辛苦移步~ 具身智能hil-serl强化学习算法在lerobot机械臂上复现
最近把hil-serl在lerobot机械臂上跑了一下,网上也没找到其他同学的成功的复现分享,所以笔者一路过关斩将解决问题,在此记录一下,希望对大家也能有所帮助。
hil-serl是2024年底的一篇文章,作者罗剑岚目前是智元的首席科学家。整体来看,其实hil-serl的思想挺简单的:传统在在线强化学习采样过程可能是算法驱动的,例如随机探索,这样效率比较低,训练时长会较长。而hil-serl就是把人类的干预引入到算法训练过程中,当自主探索不太符合预期的时候,就人工实时的纠正一下,最开始的时候可能需要纠正的频次较高,笔者经过两个小时的训练后,过程中会有肉眼可见的纠正的频次降低。整体相当于人工提升采样效率。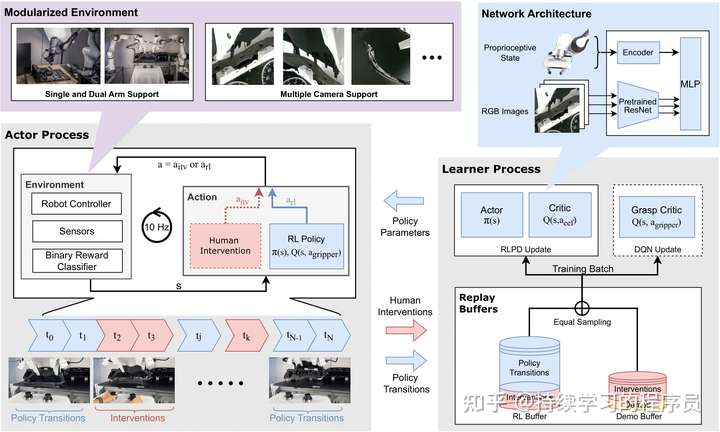
hil-serl框架
如上所述,hil-serl本身算法并没有特别高深的。笔者复现并不是基于hil-serl官方论文的代码,而是复现了lerobot库中hil-serl的实现。lerobot中的hil-serl内部使用了SAC强化学习算法,如果对此算法不熟悉,建议大家可以学习stable baselines3库中它的实现,里面有现成的仿真环境可以直接跑起来,代码也易读,效率更高一些。看明白后再来看hil-serl中对SAC的集成会很容易。虽然lerobot中已经实现了hil-serl的流程,但bug实在是太多了,笔者严重怀疑当前代码库没有经过认真测试。所以笔者不得不详细阅读相关代码,不断解决遇到的问题,终于花了几天功夫才完整的跑出一个不错的效果。
本文中不深入讲算法原理,按照lerobot中hil-serl的文档流程来复现,分享复现过程中遇到的问题,把一些bug fix的代码和配置文件也分享出来。
测试任务:
用机械臂推一个盒子到目标区域。如下图所示,用机械臂将圆形的小盒子从起始位置推到桌面上蓝色的目标区域。
任务场景
硬件依赖:
一个lerobot机械臂,从臂即可,不需要主臂,因为通过键盘来控制从臂采集数据和接管
键盘,运行过程中用键盘接管干预。lerobot官方文档建议用游戏手柄,当时不确定能否复现成功,所以就直接用键盘进行测试,一路下来,除了bug多一些(已解决,后面会分享),也挺顺手。
GPU。训练过程中默认batch size=256时,显存使用11个G不到,笔者使用的是nvidia 3090
一个相机。特意买了个腕部相机,结果没用上,因为笔者复现的任务是不需要抓手精细操作,所以直接就用一个侧方相机即可。
代码库:
笔者跑通的代码已经提交到了github,分支:hil-serl,提交记录:提交记录
复现流程:
1,确定机械臂的活动空间
执行官方文档中的lerobot-find-joint-limits命令即可
lerobot-find-joint-limits --robot.type=so100_follower --robot.port=/dev/ttyACM0 --robot.id=my_awesome_follower_arm --teleop.type=so100_leader --teleop.port=/dev/ttyACM1 --teleop.id=my_awesome_leader_arm
此命令对应的代码笔者有修改如下,也就是将机械臂描述文件直接写在代码中(因为命令行参数传递不进来)。描述文件在github中下载。注意用的是so101_new_calib.urdf,而不是so100,so100试过不能正常work。
kinematics = RobotKinematics(‘/home/ubuntu/Downloads/embodient/SO-ARM100/Simulation/SO101/so101_new_calib.urdf’, ‘gripper_frame_link’)
命令输出如下,请记录输出结果后续会在配置文件中使用:
Max ee position [0.2417 0.2012 0.1027]
Min ee position [0.1663 -0.0823 0.0336]
Max joint positions [-20.0, -20.0, -20.0, -20.0, -20.0, -20.0]
Min joint positions [50.0, 50.0, 50.0, 50.0, 50.0, 50.0]
原理介绍:
确定活动空间主要是防止机械臂运动超出合理范围导致危险情况发生或损坏机械臂。这里需要特别说明一点,以前笔者在复现act,rdt,openvla,pi0.5等模型时,用的都是机械臂的joint关节角度控制,但在hil-serl中用的是ee控制。关节角度是机械臂六个关节的角度,ee就是末端抓手的坐标(在本项目中只使用了x,y,z坐标,没有使用roll,pitch,yaw角度)。至于为什么用ee控制,原因文档有说明如下,简单翻译一下就是ee控制适合在强化学习中使用。
Empirically, learning in joint space for reinforcement learning in manipulation is often a
harder problem - some tasks are nearly impossible to learn in joint space but become
learnable when the action space is transformed to end-effector coordinates.
所以基于上面的机械臂描述文件,可以用动力学或逆动力学完成ee和joint之间的互转。在本项目中动作action就是ee坐标系下,最终物理设备底层下发的仍然是joint。
坐标系:
如下图所示,ee坐标系是一个右手系,机械臂正前为x轴,左侧为y轴,向上为z轴。原点位置在底座的某个位置(不重要),下图中的原点位置仅供参考。所以上面命令若输出:Max ee position [0.2417 0.2012 0.1027],就代表抓手最大在x轴上运动范围的最大值是0.2417米。
安全加固:
笔者在测试的过程中发现虽然lerobot框架对ee的范围有安全限制,但这个限制有bug。因为虽然ee的运动范围在安全可控的范围,但将ee通过逆运动学转换为joint后,少数情况下有可能有多个解,这些解差异会很大,若下发到机械臂,就直接导致机械臂快速移动到一个非预期的位置。所以笔者又做了一层安全加固,原理就是在joint层面尽量避免出现较大的跳动。代码提交在robot_kinematic_processor.py中。在此不再详述。
2,采集数据
在采集数据之前,先把键盘快捷键说一下。
键盘快捷键:
在键盘接管或遥操上面,笔者还是遇到了很多问题,好在是都fix了。代码提交在teleop_keyboard.py中。总结一下:
在 ubuntu中,功能键例如ctrl,shift的使用有些问题,所以笔者将所有的快捷键都设置成了字母键。例如w代表x轴方向正方向,s代表负方向;a代表y轴正方向,d代表负方向;f代表z轴正方向,v代表负方向;在遥操的时候,想让抓手末端往x轴正方向移动,就一直按下w即可。因为控制频率是10hz,在某时刻,若键盘w键处下按下的状态,那么此时刻的action中的delta_x=1,代表移动1*0.005=0.5cm
除了上面的移动按键外,笔者也定义了一些功能性按键。例如m代表标记本次episode成功;n代表开启接管状态;b代表结束接管状态;r代表重新采集此episode。接管状态笔者改成了状态维护机制,也就是开启后类内会一直维护接管状态,在这种状态下可以操作其它移动性的按键。为什么要改为状态维护机制呢?因为两个字母键同时按下的话,键盘的输入是不太稳定的,不能确定此时到底按下的是哪个键。所以改为状态维护机制,就可以使接管状态和移动指令同时存在。
以上所有快捷键大家可自由定制。另外,建议多练习一下用键盘遥操,一个熟练的操作对后续的人工干预训练效果是有帮助的。
数据采集:
在数据采集之前,建议先测试一下ee控制是否ok。例如启动采集任务,连续控制机械臂向x轴正方向移动,机械臂抓手走的是一条直线且与x轴平行。同理y轴和z轴也一样。测试没问题再进行后续流程。
在这里用键盘控制(ee控制)从臂去采集数据,hil-serl在算法框架中需要手动采集一小部分(约20episodes)数据,叫offline data。运行如下命令。若需要游戏手柄采集,笔者没试过,需要您自行研究一下。在正式采集之前,先采集1个episode用于后面的图片裁剪。
python -m lerobot.rl.gym_manipulator --config_path env_config.json
配置文件内容如下,官方文档最大的问题就是讲了很多细节,却没有直接给出一个在不同场景(例如so100+键盘场景)下能用的配置文件,下面的配置文件是经过大量测试后形成的可用配置文件,有部分重要的配置笔者直接在文件中注释,若需要此文件,建议直接从代码库下载。
{
“env”: {
“name”: “real_robot”,
“fps”: 10, // hil-serl用10hz控制频率
“processor”: {
“control_mode”: “keyboard”,
“observation”: {
“display_cameras”: false,
“add_joint_velocity_to_observation”: true, // 在默认6维的observation(关节角度)中添加一些更多的信息
“add_current_to_observation”: true // 在默认6维的observation(关节角度)中添加一些更多的信息
},
“image_preprocessing”: {
“crop_params_dict”: {
“observation.images.top”: [131, 20, 240, 493] // 图片裁剪,下面会讲
},
“resize_size”: [128, 128] // 最终图片会缩减到128*128以减少训练时间
},
“gripper”: {
“use_gripper”: true, // 设置为false会有bug,在项目和代码中不用gripper,代码有修改,下面会讲
“gripper_penalty”: 0.0
},
“reset”: {
“reset_time_s”: 5.0, // 每个episode完成后会有5秒的重置时间,重置时间内可以手动的恢复一下现场,例如让物体恢复初始位置
“control_time_s”: 20.0, // 每个episode默认20秒,可以提前结束,但超过20秒后直接会切换到下一个episode
// 下面是六个joint的初始角度,每个episode开始机械臂会重置恢复到此角度
“fixed_reset_joint_positions”: [ 35.7802, 27.3407, -12.8791, 84.6154, 21.9341, 2.1277],
// 当在20秒内提前完成了任务时,就直接切换到下一个任务,若为false,会等待直到20秒时再切换
“terminate_on_success”: true
},
"inverse_kinematics": {
"urdf_path": "/home/ubuntu/Downloads/embodient/SO-ARM100/Simulation/SO101/so101_new_calib.urdf",
"target_frame_name": "gripper_frame_link", # 不用改
// 下面的这些值就是上面lerobot-find-joint-limits命令的执行结果
"end_effector_bounds": {
"min": [0.0084, -0.1797, -0.1024],
"max": [0.3647, 0.1749, 0.2556]
},
// 每次移动0.005米
"end_effector_step_sizes": {
"x": 0.005,
"y": 0.005,
"z": 0.005
}
}
},
"robot": {
"type": "so100_follower",
"port": "/dev/ttyACM0",
"id": "my_awesome_follower_arm",
"use_degrees": true,
"cameras": {
"top": {"type": "opencv", "index_or_path": 0, "width": 640, "height": 480, "fps": 30}
}
},
"teleop": {
"type": "keyboard_ee",
"use_gripper": true
}
},
“dataset”: {
“repo_id”: “hxdoso/push_cube82”,
“root”: null,
“task”: “pick_and_lift”,
“num_episodes_to_record”: 20,
“replay_episode”: 0,
“push_to_hub”: false
},
“mode”: “record”,
“device”: “cuda”
}
部分参数介绍:
add_joint_velocity_to_observation/add_current_to_observation会在observation中增加一些额外的信息,例如关节运动速度等,这些信息在一些动态任务(动作执行非常快的任务,例如论文中的颠锅,用鞭子抽打出积木等任务)会比较有用。在这里笔者也默认留着了,去掉后效果会有何变化,后续有时间可再测试。
end_effector_step_sizes在x/y/z上都是0.005,因为键盘控制的是相对变化量,是离散的,相对当前ee的位置 。+1就代表在某个坐标轴上运行10.005=0.5cm的位移,-1就代表在某个坐标轴上运行-10.005=-0.5cm的位移。
图片裁剪:
先采集1个episode的数据,然后可运行以下命令进行图片裁剪参数的确定。目标就是去掉图片中无关的部分,因为强化学习对一些干扰比较敏感,例如场景中走过的人等背景物体。所以裁剪的目标就是尽量只留下与任务相关的部分。
python -m lerobot.rl.crop_dataset_roi --repo-id hxdoso/push_cube82
在笔者的环境中,上面的命令会失败,所以相关参数笔者是手动量出来的。确定后参数如下:
“observation.images.top”: [131, 20, 240, 493] #(top, left, height, width)
把这个参数放在上面的配置文件中,然后再采集最终要用的数据。这样数据集在存储的时候就会先裁剪图片,然后再resize成128*128保存。
demo数据:
将crop参数配置到配置文件后,就可以进行小量的offline data的采集了。笔者采集了12个episode的数据,上传到了hugging face,地址:MrXuan/push_cube,此数据可供参考格式,但对您的模型训练没有用,因为笔者与您的场景环境不一样。
3,训练Reward Classifier(可选)
Reward Classifier就是自动检测当前任务是否完成,若完成就自动触发切换到下一个episode(若terminate_on_success参数为true),同时记录一个稀疏的reward=1,本质上就是替代了上面键盘快捷键中的m按键的功能。为什么有这个功能呢,目标就是尽量减少hil-serl中人工的工作量,如果没有这个功能的话,就需要人工判断此episode是否成功了,若成功就要按m键记录reward并开启下一个episode(若terminate_on_success参数为true)。
笔者把这个reward classifier功能跑通了,但实际运行过程中发现它的分类效果不是特别稳定,可能与采集的数据太少,场景单一有关系。后面就把此功能关闭了,所以就人工用m键进行控制了。建议刚开始复现hil-serl的同学先忽略本章,改用键盘控制。后续想要尝试此功能,再来实现它。
采reward classifier的训练数据:
采训练数据的时候,terminate_on_success参数需要设置为false,是因为需要较多的正样本数据,模型训练的效果才会好。模型的训练数据也是从采集数据中提取,被键盘m键标记为成功的那一帧就是正样本,其余的帧为负样本。若terminate_on_success为true的话,此episode成功后会立即切换到下一个episode,相当于本episode中正样本帧数只有最后那一帧。所以为false的话,不会立即切换到下个episode,剩下的时间内一直按着m键的话,后面所有的帧都是正样本。
采数据用的配置文件是:env_config_capture_reward.json。命令:
python -m lerobot.rl.gym_manipulator --config_path env_config_capture_reward.json
笔者采了12个episode,每个20秒,每episode共20秒*10hz=200帧左右的图片。其中前8个epiode大概前10秒推圆盒,推到目标区域后保持不动,然后一直按m键记录成功状态。后面4个episode笔者没有移动夹抓,直接手动将圆盒放进了目录区域的随机位置,且一直按m键记录成功状态,目的是避免夹抓的位置干扰model对成功的判断。最终训练后在训练集上成功率98%以上
训练reward classifier:
lerobot-train --config_path reward_classifier_train_config.json
配置文件已经提交在代码库。笔者提交的配置文件中有两个相机,大家按需配置。训练完成后,可以在采集数据的配置文件或者后续强化学习训练的配置文件中增加相关配置,这样就不用再按键盘的m键了。
“reward_classifier”: {
“pretrained_path”: “path_to_your_pretrained_model”,
“success_threshold”: 0.7,
“success_reward”: 1.0
},
reward classifier模型简介:
1,每个图片经过ResNet10提取256维特征向量
outputs.shape
Out[2]: torch.Size([16, 256]) #batch size=16
2,两张图片特征拼接在一起经过mlp预测一个概率,然后经过二分类交叉熵监督学习
输出概率
logits.shape
Out[5]: torch.Size([16, 1]) #batch size=16
4,训练actor-learner
下面就到了hil-serl的核心模型训练流程部分了。架构设计上采用了分布式actor和learner架构进行训练。这种架构将机械臂交互与学习过程解耦,允许它们同时运行而不会相互阻塞。actor获取机械臂的观察(observation),然后策略模型推理出action(若人工接管的话,就是人工下发的action)下发到机械臂,拿到reward和next observation,这些数据整体组装成一个transition,将transition发送到learner。learner执行sac强化学习算法,并定期将策略参数发送给actor。
actor与learner之间通信协议:
下面的proto定义就是它们的通信协议,若对grpc比较熟悉的话,一眼就可以看出它的工作原理。核心就是前两个函数,StreamParameters就是learner定期将最新的策略参数发送给actor,也就是actor用最新的策略与环境之间进行交互或探索。SendTransitions就是actor将探索或交互的数据发送给learner进行模型训练。SendInteractions是一些统计信息,可暂不关注。在以下协议中参数或返回值中的stream代表它是一个数据流,也就是某一方会持续不断的发送。
service LearnerService {
// Actor -> Learner to store transitions
rpc StreamParameters(Empty) returns (stream Parameters);
rpc SendTransitions(stream Transition) returns (Empty);
rpc SendInteractions(stream InteractionMessage) returns (Empty);
rpc Ready(Empty) returns (Empty);
}
配置文件:
名为rl_train_config.json,已提交在代码库。learner与actor的配置文件都是这一个。下面对部分参数进行介绍:
dataset:就是上面采集的offline data数据集。下面对其使用原理会有详细介绍。
observation.state:shape为18维,就是6维的关节角度还有上面所讲的其它附加信息。
action:shape为3维,就是x,y,z控制。默认上面的采集数据中动作是4维,其中最后一维是夹抓。所以在learner&actor只裁剪并使用了前三维,涉及到的代码修改下文有介绍。
observation.state的统计信息:请用上面采集数据集目录下的统计信息填充此配置文件。
num_discrete_actions:此参数需要设置为null,在一些机械臂中,部分动作的维度是离散的,例如夹抓,可能只有开/合两种状态,所以sac算法中针对这类的动作,用discrete_critic进行学习。对于常规的连续型的动作,就是用连续型的critic进行学习。(对于离散型的动作,动作的个数是确定的,所以可用critic同时预测所有动作的强化学习Q值,然后Q值最大的就是目标动作。对于连续型的动作,需要用actor先infer出动作[均值/方差],然后采样出一个动作,交给critic进行Q值的计算。这里补充一些基础知识,若有疑问大家请自行检索学习)。此参数设置为null,就意味着本项目中所有的action都是连续型的。大家可能会有疑问,上面的动作[0., 0., 0., 1.]不看起来不是离散型的吗?确实是,人工下发的动作是离散型的,但策略下发的动作如[ 0.9057, 0.8559, -0.8128, 1.0000]所示,是连续型的,所以就整体看作是连续型的,把人工的动作当连续型的处理。
action维度裁剪:
在采数据环节,采集到的动作是四维的,x/y/z/gripper,但在模型推理或训练时,使用的前三维,涉及到部分代码的修改如下(均已提交):
src/lerobot/rl/actor.py:
action = policy.select_action(batch=observation)
-
added_action = torch.ones((action.shape[0], 1), device='cuda:0') -
action = torch.cat((action, added_action), dim=1) # add gripper
src/lerobot/rl/learner.py
-
ACTION: actions,
-
ACTION: actions[:, :3], # only keep x&y&z
learner中buffer介绍:
如下图所示,有两种数据buffer。右侧中的Demos就是上面采集的offline data。右侧的Interventions就是hil-serl训练过程中的人工接管数据。左侧的interventions跟右侧一致。左侧的policy transitions就是策略与环境进行交互或探索过程中的自动化交互数据。这两部分数据在训练过程中会等比例获取,例如batch size=256,那么两个buffer中各取128条。
上图中的interventions和policy transitions数据是从actor进程发送给learner进程,若是interventions数据,就同时放在两个buffer中。此部分代码逻辑中有bug,已fix,代码如下:
src/lerobot/rl/actor.py
actor发送的数据中需要包含接管信息
-
TeleopEvents.IS_INTERVENTION: intervention_info.get(TeleopEvents.IS_INTERVENTION, False),
src/lerobot/rl/gym_manipulator.py -
info always set IS_INTERVENTION=False
-
info.pop(TeleopEvents.IS_INTERVENTION, None)
learner中相关模型的网络结构:
共享特征提取:
learner中的actor与critic共享一个特征提取网络,叫shared encoder ,其输出维度:
512=256(image,由resnet10提取)+256(state,由mlp输出)
critic:
在上面共享的特征提取基础之上,再+3(action,原始数据拼接),然后送进下面的head
critic head:
515—mlp—>256—linear—>1
共有2个critic head,就是sac算法中的双critic设计, 同时有2个critic_target head,也是sac算法中的target网络设计,目的是保持训练的稳定性。
actor:
特征提取与critic共享,输出512维向量。
actor head:
512—mlp—>256------linear—>3(action dim,输出动作均值)
|
|-----linear—>3(action dim,输出动作方差)
self.mean_layer
Out[4]: Linear(in_features=256, out_features=3, bias=True)
self.std_layer
Out[5]: Linear(in_features=256, out_features=3, bias=True)
启动训练进程:
用下面命令启动learner:
python -m lerobot.rl.learner --config_path rl_train_config.json
用下面命令启动actor:
python -m lerobot.rl.actor --config_path rl_train_config.json
让actor的进程保持在活动状态,然后通过键盘按需接管。接管操作的快捷键跟上面采集数据是完全一样的。
笔者第一次训练,坚持了两个小时的时间,终于训练出较好效果的一版模型,因为是第一次长时间human in the loop,所以不熟练,出现一些意料外的问题,例如中间机械臂失控导致机械臂整体位移了,又重新还原相机臂。估计多来几次整体出效果的时间会进一步缩短。
特别说明一点是,由于运动学或逆运动学转换的不确定性,机械臂会出现较大幅度的抖动或位移,虽然上面有安全加固方案,但并不能彻底解决问题,所以会偶发机械臂位移过大,导致actor进程整体抛异常退出。此时就直接再次重启actor就可以了。笔者在训练过程中大概发生过三次。learner进程较为稳定,并没有退出的情况。
一些训练曲线图:
loss曲线图说明模型基本收敛了。
下面两个buffer size的变化曲线图也说明了相关bug已经fix,这些buffer的设计原理与hil-serl原始论文是一致的。
训练过程视频:
下面视频是训练过程的交互,其中大概有三段是人工接管操作的,其它的都是policy自动化下发的。它们之间仔细观察可以看出有些不同,人工接管在操作有顿挫,不连续,而策略下发的就丝滑一些。
您看到这里,笔者写到这里都不容易,顺手点个赞吧~
更多推荐

 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)