TPAMI 2025 | 告别ResNet!UniMatch V2 以ViT新基线+互补Dropout突破半监督语义分割性能上限
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达半监督语义分割(SSS)作为降低密集标注成本的关键技术,近年来在算法设计上陷入了微创新困境。清华大学大学团队提出的UniMatch V2框架,通过引入用强预训练视觉Transformer编码器与优化框架设计,在四大主流数据集上刷新性能纪录,为该领域发展指明了新方向。
论文信息
题目:UniMatch V2: Pushing the Limit of Semi-Supervised Semantic Segmentation
UniMatch V2:突破半监督语义分割的极限
作者:Lihe Yang, Zhen Zhao, and Hengshuang Zhao
研究背景与动机
语义分割作为场景理解的核心任务,其性能提升高度依赖大规模像素级标注数据。以Cityscapes数据集为例,单张图像的标注需1.5小时,这极大限制了模型在标注资源匮乏场景的应用。半监督语义分割通过融合少量标注数据与大量未标注数据进行训练,成为降低标注成本的有效方案。
现有SSS研究存在两大局限:一是持续采用基于ImageNet-1K预训练的ResNet编码器,未能跟进视觉Transformer(如DINOv2)的技术进展;二是评估集中于Pascal和Cityscapes等简单数据集,对复杂场景的泛化能力研究不足。实验表明,仅将编码器从ResNet-101替换为参数更少的DINOv2-S,即可在Pascal数据集实现3%的性能提升,Cityscapes数据集提升4%,揭示了编码器升级的巨大潜力。
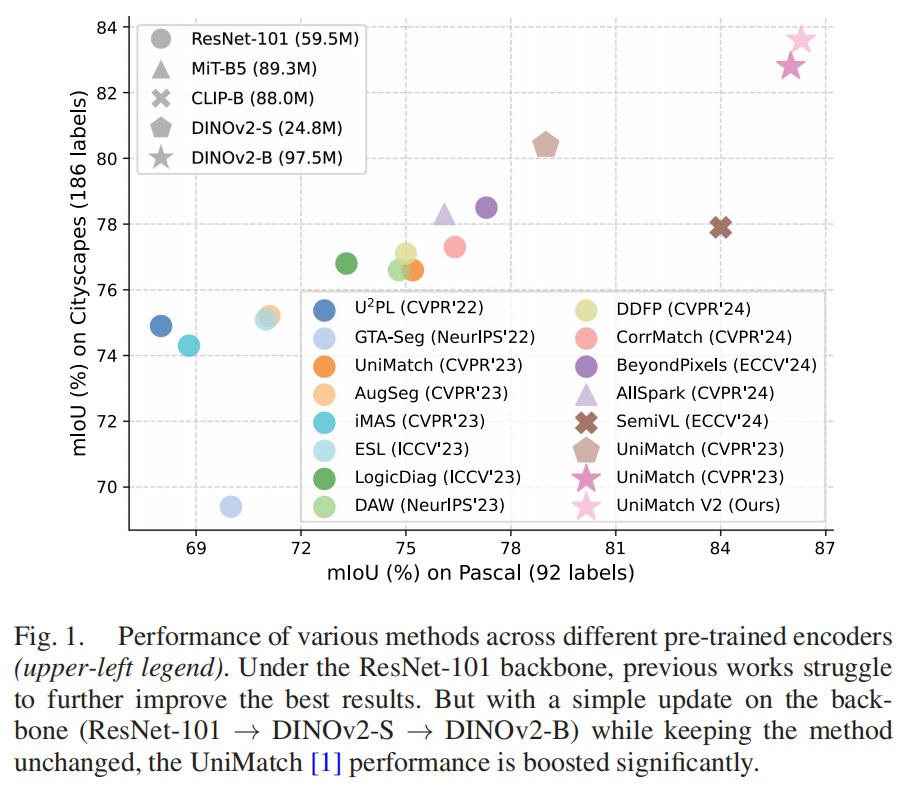 不同编码器在半监督语义分割任务上的性能对比,显示DINOv2系列编码器的显著优势
不同编码器在半监督语义分割任务上的性能对比,显示DINOv2系列编码器的显著优势
方法框架详解
技术演进脉络
UniMatch V2基于FixMatch的"从弱到强一致性正则化"思想发展而来,其演进过程体现了"简化架构+强化核心"的设计哲学:
-
FixMatch基础框架:通过弱增强图像生成伪标签,监督强增强图像的预测结果,实现端到端半监督训练。该框架包含一个伪标签生成流和一个强增强学习流,通过置信度阈值筛选可靠伪标签。
-
UniMatch V1改进:引入双流增强策略,在图像级和特征级分别构建增强流,通过三个并行学习流强化一致性约束。但特征级增强流在强编码器下贡献有限,且多流设计增加了计算成本。
-
UniMatch V2创新:融合输入级与特征级增强为单流结构,设计互补通道Dropout机制,在保持性能提升的同时降低33%计算量。
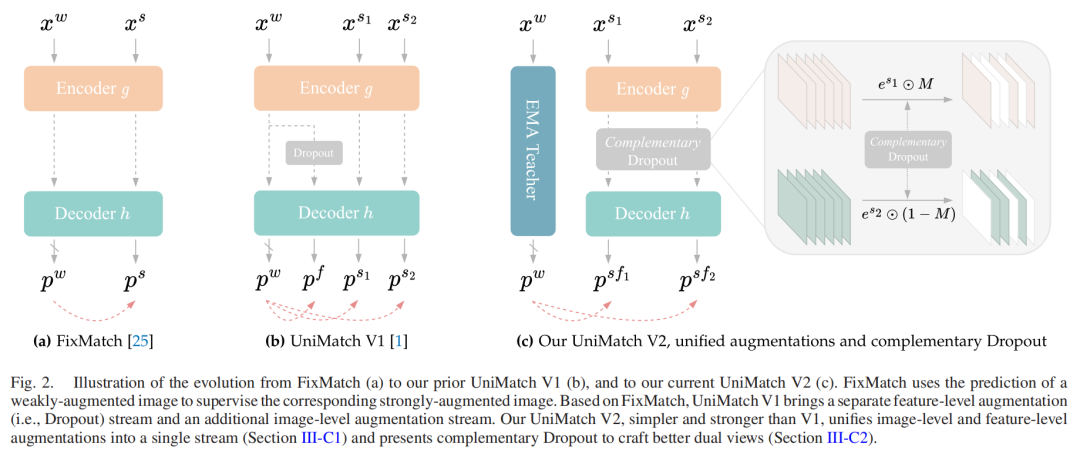 (a)FixMatch框架 (b)UniMatch V1框架 (c)UniMatch V2框架的结构对比
(a)FixMatch框架 (b)UniMatch V1框架 (c)UniMatch V2框架的结构对比
核心创新点
-
单流统一增强机制:实验发现DINOv2编码器对特征级增强的敏感性显著降低(特征级损失仅为图像级的1/6),因此将输入级强增强(颜色抖动、CutMix等)与特征级Dropout融合为单一流程。该设计在保持增强空间完整性的同时,大幅提升训练效率。
-
互补通道Dropout:通过二进制掩码将特征通道随机划分为两个互补子集,分别保留纹理与结构信息。与V1的随机双增强相比,该方法能生成更具判别性的双视图特征,增强模型对特征扰动的鲁棒性。掩码设计确保两个子集通道数相等,通过缩放因子维持特征尺度一致性。
-
教师-学生模型优化:引入指数移动平均(EMA)教师模型生成伪标签,解决学生模型预测波动问题。教师模型参数通过动态权重更新策略,在训练过程中逐步收敛至稳定状态。
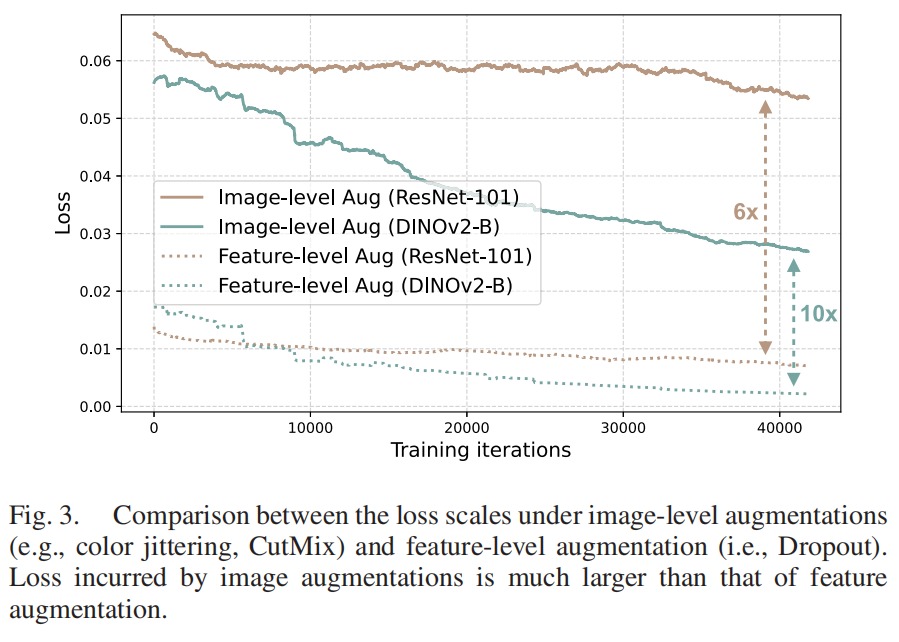 特征级增强与图像级增强的损失对比,揭示特征级增强在强编码器下的有限贡献
特征级增强与图像级增强的损失对比,揭示特征级增强在强编码器下的有限贡献
实验验证与分析
数据集与实验设置
研究在四大主流数据集上进行全面评估:
-
Pascal VOC 2012:21个类别,1464张标注图像
-
Cityscapes:19个城市场景类别,2975张高分辨率标注图像
-
ADE20K:150个复杂场景类别,20210张标注图像
-
COCO 2017:81个类别,118287张标注图像
实验采用DPT作为解码器,对比DINOv2-S/B与ResNet、CLIP等编码器的性能差异。训练采用AdamW优化器,预训练编码器与随机初始化解码器分别设置学习率5e-6和2e-4,采用多项式学习率调度策略。
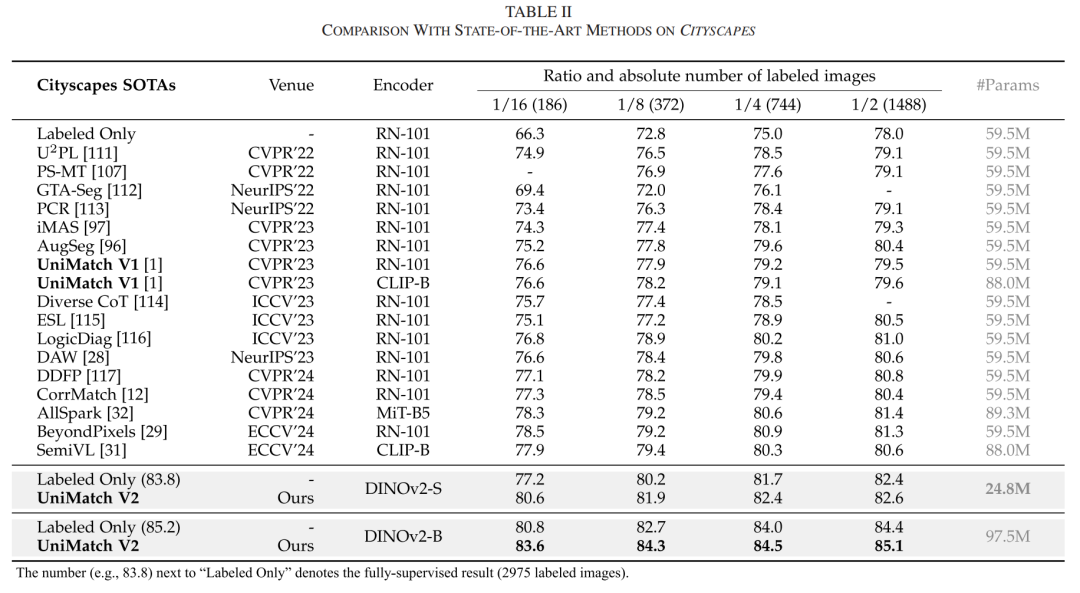
关键实验结果
-
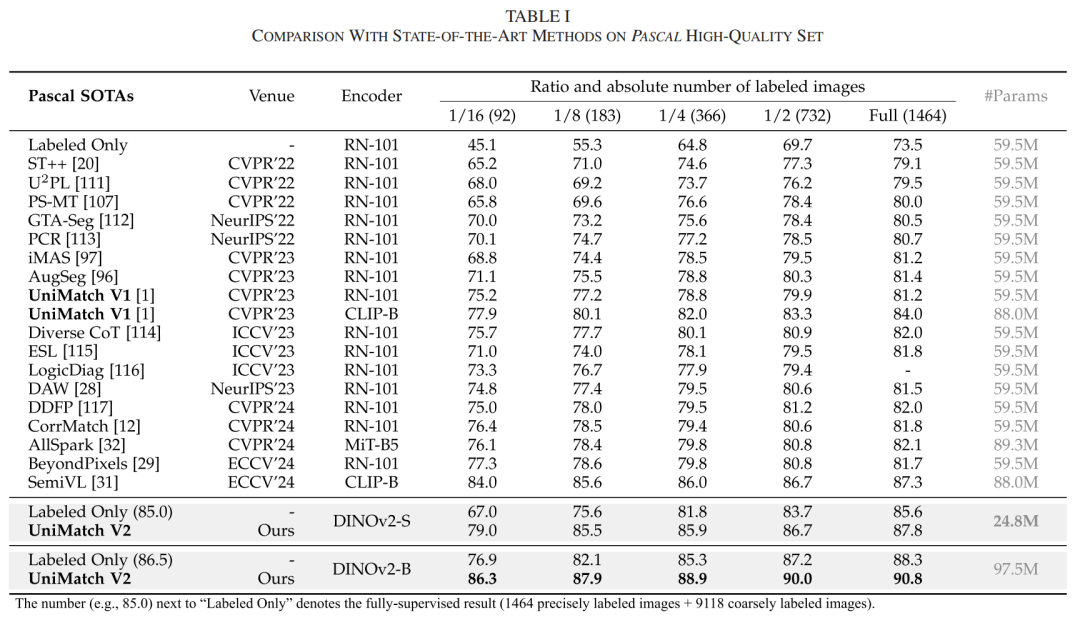
跨数据集性能突破:
-
在Pascal数据集1/8标注设置下,DINOv2-S实现85.5% mIoU,较ResNet-101提升6.9%
-
Cityscapes 1/16标注设置中,DINOv2-B达到83.6% mIoU,超CLIP-based方法5.7%
-
ADE20K 1/8标注设置下,较SemiVL提升10.4%(49.8% vs 39.4%)
-
COCO 1/128标注设置中,从V1的44.4%提升至53.2%
-
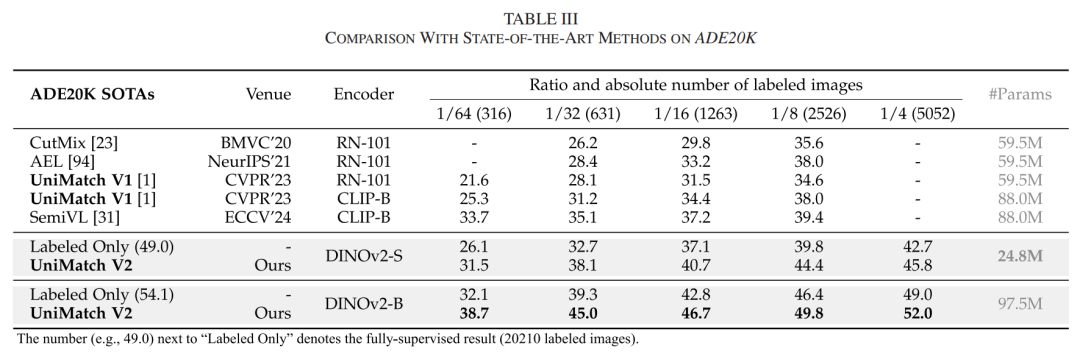
消融实验验证:
-
互补Dropout在各数据集上带来1.2-2.3%的性能提升
-
单流设计保持性能的同时减少33%计算量
-
教师模型EMA策略稳定伪标签质量,提升约0.8% mIoU
-
泛化能力测试: 在遥感变化检测和图像分类等半监督场景中,UniMatch V2同样表现出优异的迁移能力,验证了方法的通用性。
-
研究意义与未来方向
UniMatch V2的成功验证了预训练编码器升级对SSS任务的变革性影响,为领域发展提供三大启示:
-
编码器优先原则:相较于复杂模块设计,采用DINOv2等现代预训练编码器可带来更显著的性能提升,应成为未来研究的基准配置。
-
评估基准升级:鉴于Pascal和Cityscapes性能趋于饱和,建议转向ADE20K和COCO等更具挑战性的数据集,以更好地衡量方法的泛化能力。
-
简洁设计理念:通过融合增强策略和优化视图生成,UniMatch V2证明简化架构可在提升效率的同时保持性能优势,为算法工程化提供参考。
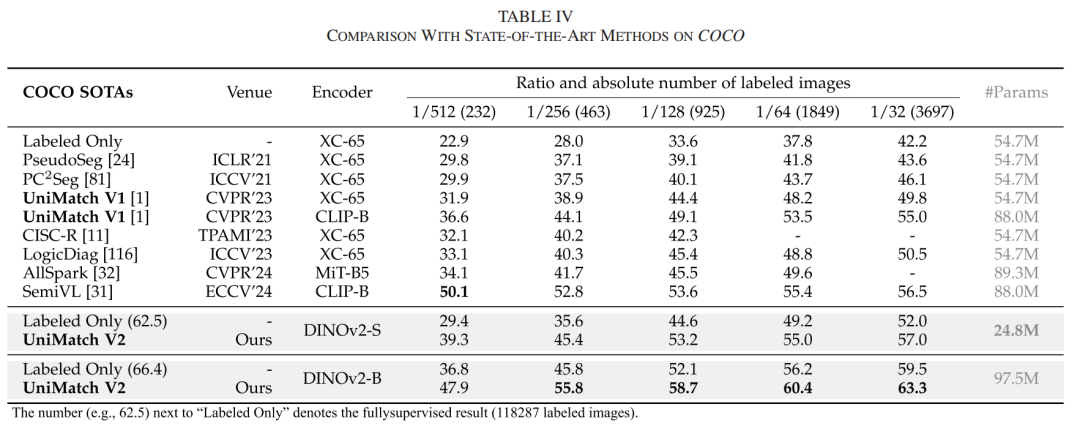
 UniMatch V2的PyTorch风格伪代码,展示其简洁的实现逻辑
UniMatch V2的PyTorch风格伪代码,展示其简洁的实现逻辑该研究不仅推动了半监督语义分割的性能边界,更为如何利用视觉基础模型赋能下游任务提供了范式参考。随着预训练模型与半监督学习的深度融合,我们有理由期待在更低标注成本下实现更高精度的场景理解。
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:人工智能0基础学习攻略手册 在「小白学视觉」公众号后台回复:攻略手册,即可获取《从 0 入门人工智能学习攻略手册》文档,包含视频课件、习题、电子书、代码、数据等人工智能学习相关资源,可以下载离线学习。 交流群 欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~ -

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)