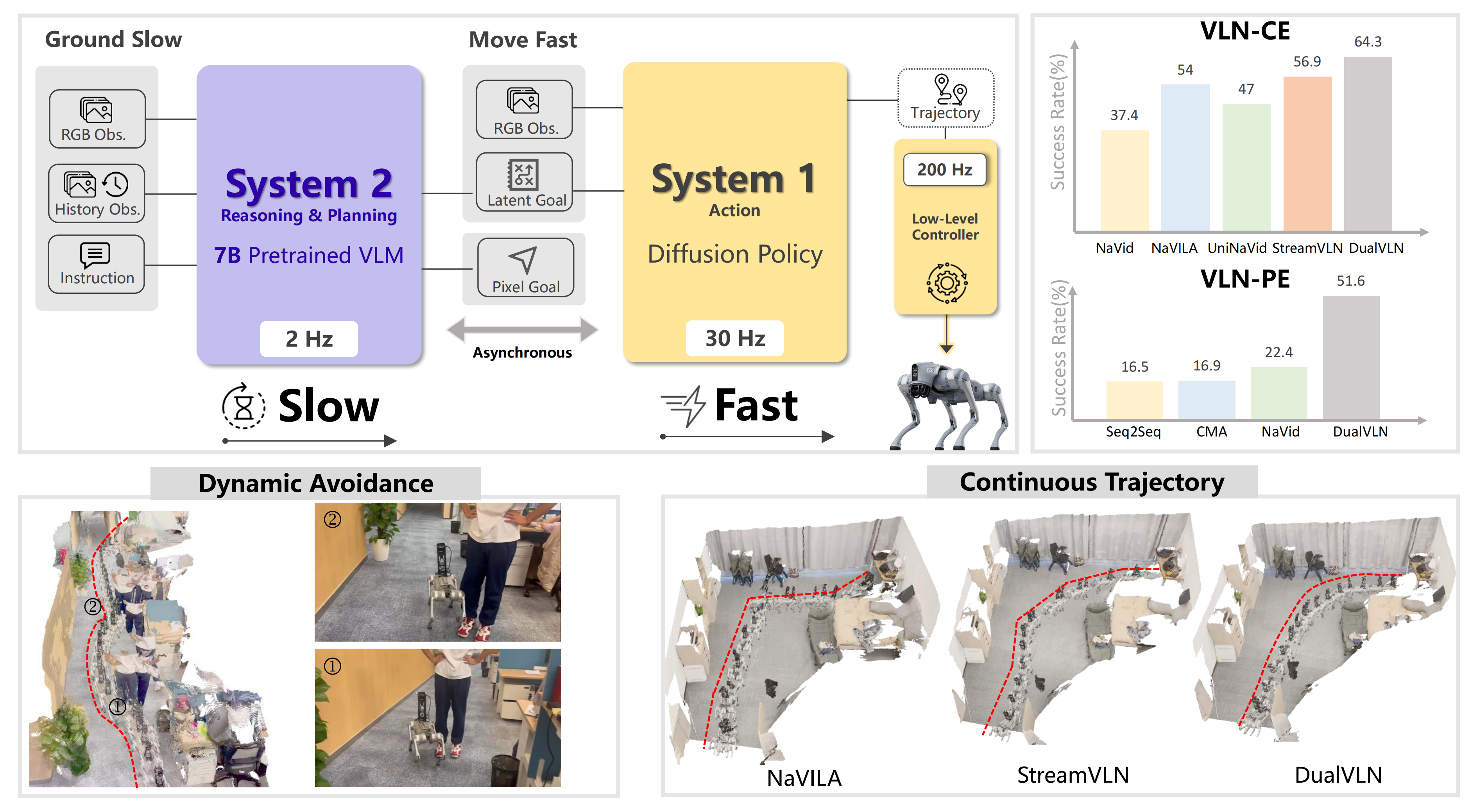
DualVLN——基于像素目标点的双系统VLN基础模型:VLM做全局规划且预测中期路径,DiT策略头依托高频RGR输入和“来自VLM的低频潜在特征”生成动作轨迹
本文提出DualVLN,首个双系统视觉语言导航基础模型,将高层推理与实时控制解耦。System2作为大型VLM进行鲁棒推理并生成像素级目标,System1作为轻量级扩散策略模型将目标转换为连续轨迹。通过潜在表示连接两个系统,System2先训练后冻结,System1通过潜在查询提取特征。这种设计使System2能利用大规模数据扩展,System1专注于高频控制。实验表明该方法在动态环境中实现了精确
前言
今天是2026年1.19日,回顾过去的十一年:2015.1.19-2026.1.19,便是我正式创业11年:8年教育 + 1年大模型开发 + 2年具身开发
若问我最大的感受是什么,我最大的感受是,再来11年,达心中理想
在最近的去年年底,2025年12月,上海AI LAB团队发布:Training code for InternVLA-N1 and the corresponding usage doc is now available. This release provides two model configurations:
且还推出了两个衍生模型
- InternVLA-N1 (Dual System) with NavDP*
详见:huggingface.co/InternRobotics/InternVLA-N1-w-NavDP - InternVLA-N1 (Dual System) DualVLN
本文则来解读后者DualVLN
第一部分
1.1 引言与相关工作
1.1.1 引言
如原论文所说,来自1 Shanghai AI Laboratory、2 The University of Hong Kong、3 Zhejiang University、4 Tsinghua University的研究者提出了首个双系统 VLN 基础模型 DualVLN,它显式地将 VLM 的推理能力与实时控制所需的敏捷性连接起来
- 其paper地址为:Ground Slow, Move Fast: A Dual-System Foundation Model for Generalizable Vision-and-Language Navigation
其作者包括
Meng Wei1,2 Chenyang Wan1,3 Jiaqi Peng1,4 Xiqian Yu1 Yuqiang Yang1 Delin Feng1 Wenzhe Cai1 Chenming Zhu1,2 Tai Wang1,† Jiangmiao Pang1,‡ Xihui Liu2,‡ - 其项目地址为:internvla-n1-dualvln.github.io
其GitHub地址为:InternRobotics/InternNav
DualVLN 将 VLN 流水线解耦为两个互补的系统
- System 2 是一个大型基础 VLM,执行较慢但鲁棒的推理,并生成显式的中间像素级目标
- System 1 是一个轻量级、基于扩散的策略模型,将已落地的目标转换为连续的可通行轨迹,从而在动态场景中实现鲁棒的避障
为更好地协调 System 1 和 System2,作者通过潜在表示将两个系统连接起来。在使用像素目标落地任务训练完 System 2之后,冻结 System 2 的权重
随后,作者引入一组可学习的潜在查询,并通过提示微调对其进行优化。这些查询提取紧凑的潜在特征,并作为 System 1 的隐式目标
- 为何采用解耦的序列式训练?
解耦使得每个系统都能各自专精:System 2 可以利用大规模、多源的推理数据进行扩展,而 System 1 只需要少量低层级的目标到达数据
System 1 还可以从高频率的额外 RGB 输入以及异步推理中获益,从而在动态环境中实现更高的控制频率
至关重要的是,这种分离在适配下游低层级规划任务时,能够保留 VLM 的泛化能力 - 为什么要同时使用显式像素目标和隐式潜在目标?
仅依赖显式的二维像素目标来为System 1 提供指导,无法充分利用 VLM 中丰富的隐藏特征,导致推理与局部规划之间的连接较为浅层,并将这一双系统退化为一种模块化流水线。学习显式像素目标有助于提升 System 2 的可解释性和泛化能力
在此基础上,隐式潜在特征则进一步为System 1 提供更丰富、更具适应性的指导,使其能够从编码在 VLM 隐藏状态中的异构信息中自动抽取与任务相关的表示
1.1.2 相关工作
首先,对于用于导航的视觉-语言-动作模型
近期研究利用多模态大模型作为导航的预训练骨干,旨在利用其内在的常识知识提升性能
- 一种常见做法是将导航动作表述为文本,将该任务视作大语言模型中的下一个 token 预测(Zheng et al. (2024); Zhang et al. (2024; 2025a); Gao et al. (2025);Wei et al. (2025); Wang et al. (2025d))
- 其他工作,如 RoboPoint Yuan et al. (2025)、NaviMaster Luo et al. (2025) 则将导航表述为像素级定位(pixel grounding),但仍然需要额外的执行模块
诸如 UniVLA Bu et al. (2025) 和 TrackVLA Wang et al.(2025c) 这样的端到端方法,将 VLM 的潜在特征直接映射到连续轨迹,但其同步式框架限制了在动态环境中进行高频决策的能力 - 尽管近期一些双系统架构 FigureAI (2025);Shi et al. (2025); Bu et al. (2024) 探索了快慢推理机制,它们主要聚焦于桌面任务,未涉及长时域规划或跨楼宇导航
故,作者提出了首个支持长时程指令执行、精确规划以及在未见环境中导航的异步双系统架构
其次,对于视觉导航策略学习
视觉导航使得在执行实时避障的同时能够到达明确的目标
- 传统的模块化方法 Fox et al. (1997); Kramer & Stachniss (2012); Karaman & Frazzoli (2011);Williams et al. (2015); Zhou et al. (2020) 依赖显式定位与建图
但会遭受误差累积、延迟以及大量超参数调优等问题 - 为解决这些问题,人们提出了端到端的学习方法:GNM Shahet al. (2023a)、X-Nav Wang et al. (2025a)、RING Eftekhar et al. (2024) 和 X-Mobility Liuet al. (2024) 提升了跨不同机器人形态的零样本泛化能力
而 iPlanner Yang et al. (2023)、ViPlanner Roth et al. (2024)、FDM Roth et al. (2025) 和 S2E He et al. (2025) 则侧重于高效训练和从仿真到真实(sim-to-real)的迁移
基于图像目标的导航也已由 SLINGWasserman et al. (2023)、ViNT Shah et al. (2023b)、NoMad Sridhar et al. (2024) 和NaviDiffuser Zeng et al. (2025) 等工作进行探索
而作者的 System-1 是一种仅依赖 RGB 输入的视觉导航策略,其条件输入为来自 VLM 的潜在目标表示
1.2 DualVLN的完整方法论
如图 2 所示,DualVLN的框架采用双系统设计,实现了高层推理与低层动作执行之间的协同
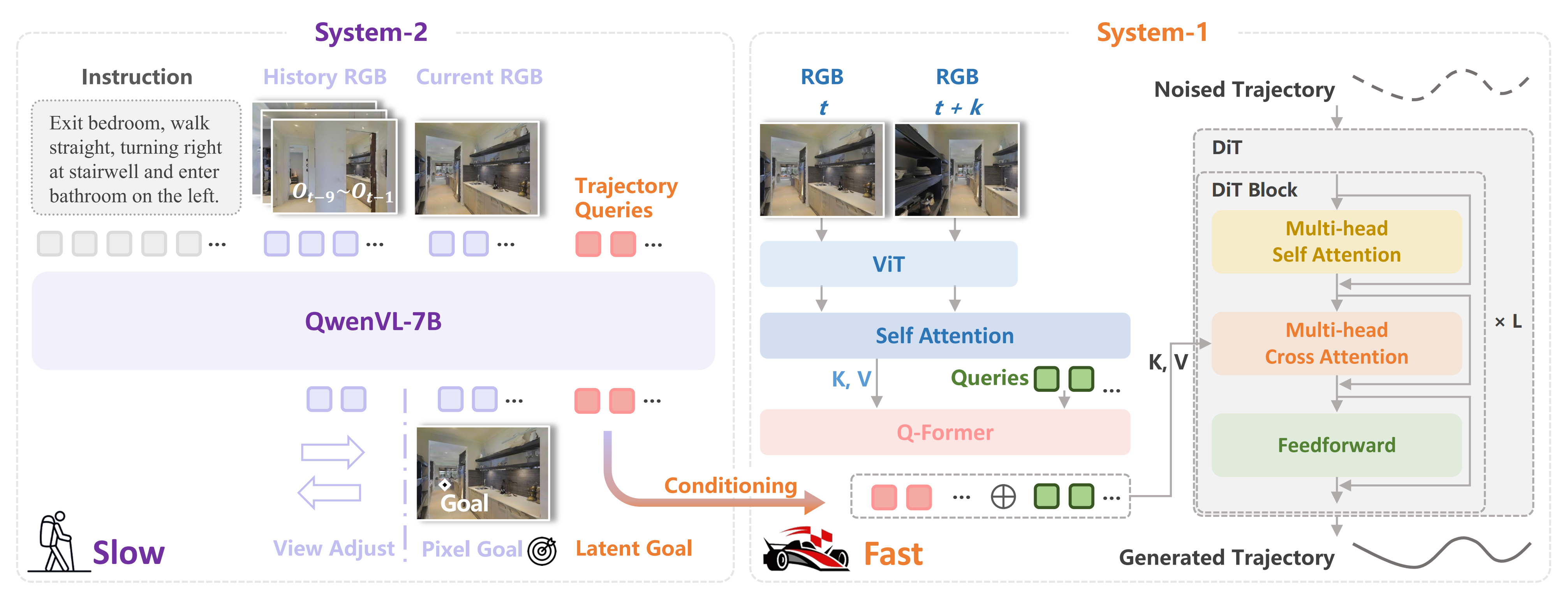
- System 2 是一个基于 VLM 的规划器,通过在图像像素空间中预测中期路径点来进行全局规划,从而提供具有空间约束的目标
System 2 的输入是一系列以自我视角采集的图像以及指令,用于预测视角调整动作,或图像中下一导航航路点对应的 2D 像素坐标
————
且遵循 StreamVLN(Wei 等,2025)的数据配方,并对 QwenVL-2.5 (7B) 微调一个 epoch。在微调过程中,视觉编码器和 LLM 主干都完全解冻 - System 1 是一个多模态、目标条件的扩散策略,在当前观测和来自 System 2 的异步潜在特征条件下生成连续轨迹,从而在复杂环境中实现鲁棒的实时控制
System 1 将潜在目标嵌入(latent goal embeddings)与高频 RGB 输入一并作为输入,通过基于扩散(diffusion-based)的策略为机器人生成连续可跟随的轨迹
1.2.1 SYSTEM2:基于 VLM 的像素目标定位与自导式视角调整
System 2 在一个迭代过程中将高级像素目标定位与自导式视角调整结合起来。在每个导航步骤中,智能体观察当前的 RGB 帧及其历史信息,并决定是调整视角还是输出一个像素目标
这样可以确保像素目标预测基于信息量充分的视角,从而处理遮挡和具有挑战性的视点
- 最远像素目标定位(Farthest Pixel Goal Grounding)
作者在 Qwen-VL-2.5 Bai etal. (2025) 之上构建目标规划模块
Qwen-VL-2.5 是一个强大的开源视觉-语言模型,能够在图像像素坐标层面进行空间定位(spatial grounding)
为了使 Qwen-VL-2.5 适用于视觉与语言导航(VLN),作者将高层规划形式化为一个最远像素目标定位问题
模型以一段自我视角的 RGB 图像序列及语言指令作为输入,并预测图像中的二维坐标,作为下一步首选导航路标
为了生成训练样本,作者将智能体的三维轨迹投影到二维自我视角观测上,并从智能体当前位置评估可见性
To generatetraining samples, we project the agent’s 3-D trajectory onto the 2-D egocentric observations and measure the visibility from the agent’s position
具体而言,在投影轨迹之前,作者利用深度图以及相机与点之间的距离来判断哪些点落在当前视野的可见区域内
对于任一轨迹点,如果其距离超过对应的深度值,则视为被遮挡并予以丢弃。基于这一投影,作者将原始的 VLN-CE 轨迹切分为像素目标定位样本 - 自主视角调整
将三维轨迹投影到二维像素坐标上可能会带来问题。如果智能体的视角过高,地面上的点可能会被遮挡,而人为地将这些点抬高又会引入深度歧义,使得实际目标所在的位置变得不清晰
此外,如果智能体面向的方向不对,下一个航点可能会落在当前视野之外。受人类导航行为的启发——人们往往会先环顾四周并将目光下移到地面,然后再选择下一个航点
如此,System 2 会自主决定何时扫描环境以及如何调整相机角度,使用诸如 Turn Left/Right 15°、Look Up/Down 15°等离散动作,在预测下一个像素级目标之前主动寻找信息更丰富的视角
1.2.2 SYSTEM1:一种具有多模态条件的扩散 Transformer 策略
首先,对于潜在目标表示
- 在System 2 自回归地生成下一个像素目标之后,模型自然会产生一个上下文特征序列
,其中包含语言指令、历史图像、当前观测、视角调整动作以及像素目标信息
After System 2 autoregressively generates the next pixel goal, themodel naturally produces a context feature sequence X encompassing the language instruction,historical images, current observations, view adjustment actions, and pixel goal information
然后附加一组可学习的潜在查询,其通过提示微调进行随机初始化和更新
We then append a set of learnable latent queries Z, which are randomly initialized and updated via prompt tuning.
即对于System 1,作者在 System 2 的像素目标预测之后附加了4个可学习的潜在查询(latent queries),以提取紧凑的潜在目标嵌入 - 通过VLM 处理组合序列
,使得
Processing the combined sequence [X; Z] through VLM enables Z to attend to andextract task-relevant semantic information from X.
得到的构成了中间潜在目标表示,用于为System 1 提供条件以进行精确的、低层次的轨迹生成
The resulting Z′ forms the intermediate latent goal representation, which conditions System 1 for precise, low-level trajectory generation.
其次,对于多模态条件扩散Transformer
System 1 被实现为一种扩散Transformer (DiT),它在两种条件源的作用下为机器人生成平滑轨迹(32 个密集航路点):
- 来自System 2 的低频轨迹潜变量
- 高频RGB 输入
由于双系统推理是异步执行的(慢速System 2,快速System 1),一方面需要,在时间 生成的潜在目标保持不变;二方面,需要在时间
,System 1 仍然必须解释这个已经过时的潜在目标以准确更新轨迹,估计已经行进的距离并适应动态变化
- 为此,系统1 对来自系统2 在时间
的最后一帧对应的RGB 特征以及在时间
的当前观测进行编码
两幅图像首先通过一个ViT 编码器进行处理,以提取高维视觉特征
————
RGB 编码器采用 Depth Anything V2-Small 的ViT 主干实现 - 然后使用自注意力模块在这两个时间步之间对这些特征进行融合
- 为保持快速推理,融合后的特征进一步通过Q-Former 压缩为一组紧凑的32 个token,它们作为DiT 的高频视觉条件输入
具体而言,作者采用紧凑的 Diffusion Transformer (DiT) 设计以确保低延迟推理,其隐藏维度为384,包含12层 transformer,以及6个注意力头。在与 DiT 进行交叉注意力之前,将潜在嵌入尺寸从3584线性映射到768。更多细节可见第 A 节
接下来,给定真实轨迹航路点 和两个条件信号(轨迹潜变量
和融合RGB token
)
- 在每一步训练中,首先采样扩散时间步
和噪声向量
- 然后将带噪轨迹定义为:
其中,是关于
的递减函数,而
是关于
- 扩散Transformer 被训练来预测在时间步
,条件为
:
其中 ⊕ 表示串联,为 Transformer 网络
- 训练目标是最小化预测速度与真实速度之间的均方误差:
1.3 实验
1.3.1 仿真实验
如表 1 所示,作者在 VLN-CE 评测下,将 DualVLN 与三类具有代表性的基线方法进行了比较:
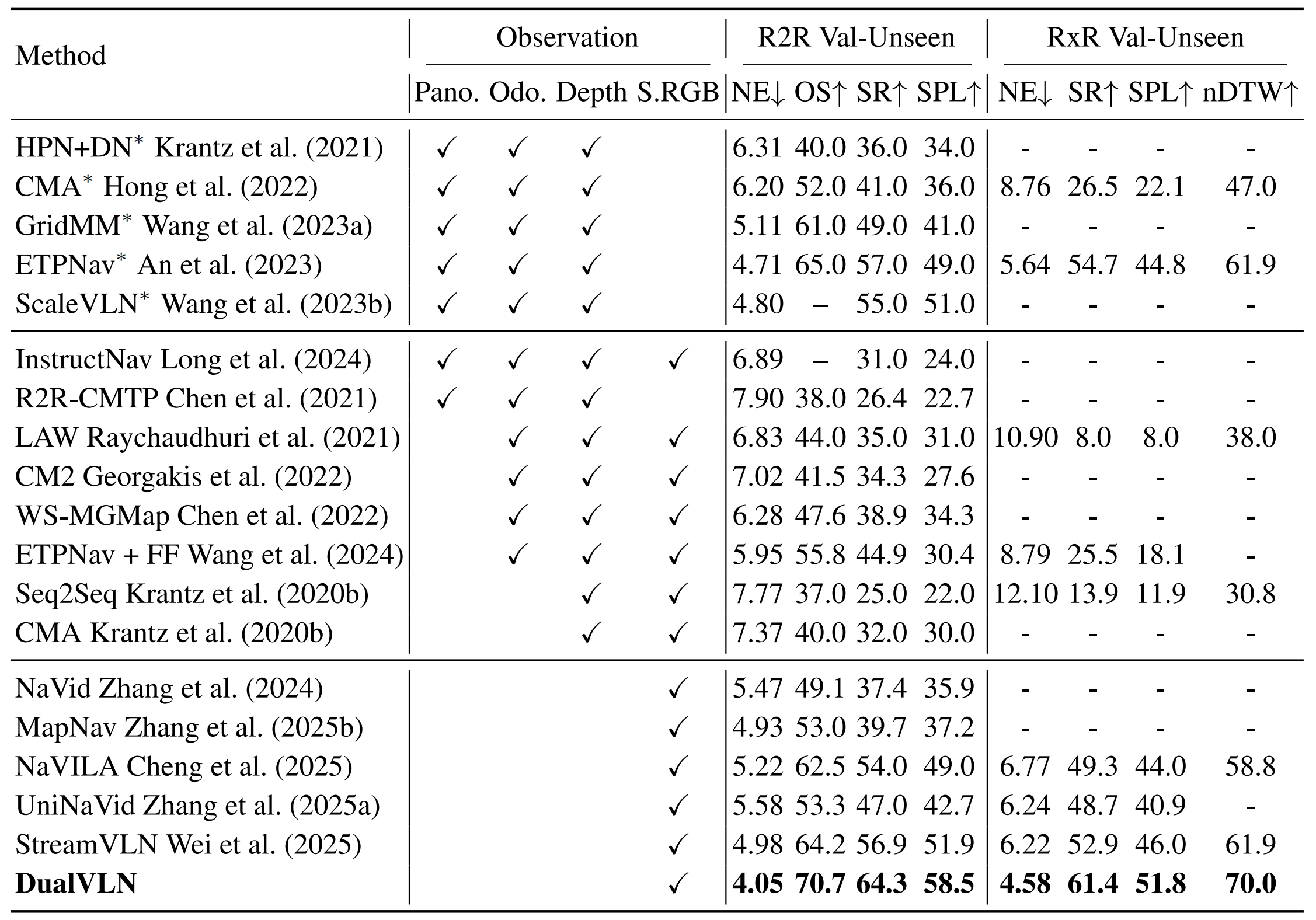
- 融合全景 RGB、里程计和深度的多传感器方法(例如 HPN+DN、CMA、GridMM、ETPNav)
- 在单一第一视角 RGB 和深度上训练、且不依赖 VLM 的方法(例如CM2、LAW、WS-MGMap)
- 仅依赖单视角 RGB 的基于 Video-LLM 的方法(例如 NaVid、MapNav、NaVILA、UniNaVid、StreamVLN)
在仅使用第一视角 RGB 输入的情况下,作者宣称,DualVLN 相比所有先前的基于 RGB 的方法都取得了大幅提升
表2报告了在物理运动控制器设置下的 VLN-PE 实验结果
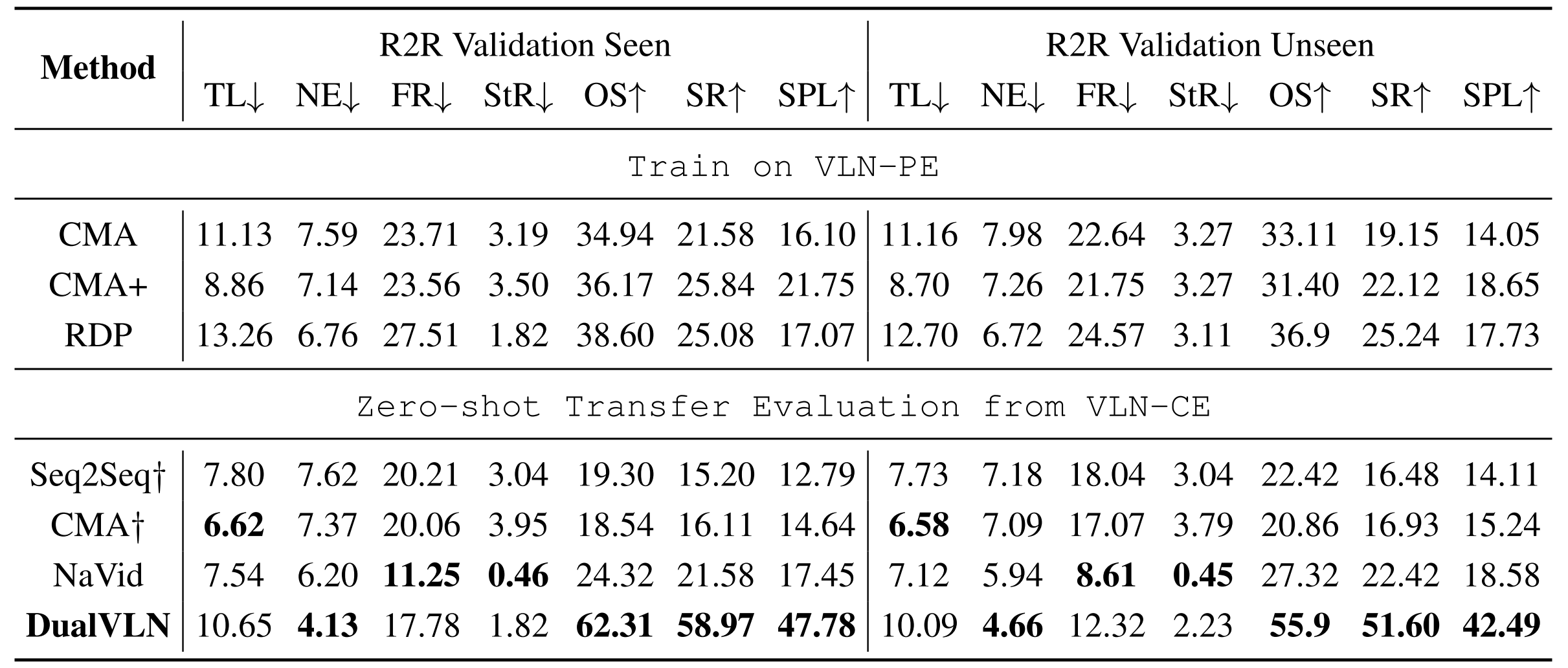
基线方法包括 Seq2Seq Krantz 等(2020b)、CMA Krantz 等 (2020b)、RDP Wang 等 (2025b) 以及 NaVid Zhang 等 (2024)
- Seq2Seq 基于 RGBD 输入并采用递归策略预测动作
而 CMA 在此基础上结合指令引入跨模态注意力机制 - RDP 引入基于 Transformer 的扩散解码器来生成连续位移
而 NaVid 则利用基于视频的大型语言模型,在无需深度或里程计信息的情况下提升泛化能力
尽管没有在 VLN-PE 轨迹上进行微调,DualVLN 仍然优于所有基线方法,包括在 VLN-PE 上训练的模型以及基于 VLM 的方法
1.3.2 真实世界跨具身实验
首先,对于实验设置
- 作者在轮式(Turtlebot4)、四足(Unitree Go2)和人形(Unitree G1)机器人上进行真实环境实验
所有机器人均配备 Intel RealSense D455 相机,安装在不同高度,并向下倾斜 15°
完整模型运行在配备 RTX 4090 GPU 的远程服务器上,占用 20GB显存 - 在给定 VLN 指令后,机器人将同步的 RGB-D 图像以流式方式发送到远程服务器,由双系统模型进行异步推理
服务器输出轨迹或离散视角调整动作,这些结果通过里程计转换为世界坐标,并由 MPC 控制器进行跟踪 - System 2 通过复用 KV-cache,将轨迹token 的推理时间从 1.1s 降低到 0.7s,而 System 1 借助 TensorRT 可在 0.03s 内并行生成 32 条轨迹
这一异步流水线确保始终有最新轨迹可用,从而实现平滑、近乎实时的导航
其次,对于定量分析
为了在真实世界环境中对 DualVLN 的鲁棒性和泛化能力进行定量评估,作者将其与
- CMAKrantz et al. (2020a)
- 以及基于 VLM 的方法
NaVid Zhang 等(2024)
NaVILA Cheng 等(2025)
StreamVLN Wei 等(2025)
进行了基准对比
————
这些方法输出离散动作
在走廊(简单)、卧室(中等)和办公室(困难,跨房间)场景下进行评估,每个模型在每种场景上各进行 20 次试验。性能采用成功率(SR)和导航误差(NE)进行度量
在图 6 所示的基于 VLM 的基线中

NaVid 在复杂任务上表现吃力,NaVILA 能处理长时域任务,但在办公室场景中经常错过最终目标。StreamVLN 在某些情况下能够避开障碍物,但以牺牲任务完成为代价
而作者宣称,他们提出的双系统 DualVLN 在静态和动态场景中都能稳定地取得较高的 SR 和较低的 NE
1.3.3 消融实验
第一,对于显式像素目标与潜在目标的影响
为评估不同目标表示在对 DualVLN 的 System-1 进行条件控制中的作用,作者按照图 7 所示进行了一系列消融实验
- 首先考虑一种不采用顺序训练的替代设计,在该设计中,System 1 与 System 2 进行端到端联合训练,并且不依赖显式像素目标
在这种配置下(w/o Sys.2 Train),作者观察到扩散策略的收敛速度显著变慢,且 System 2 的泛化能力有所退化
这表明,利用中间像素目标进行解耦训练对于实现高效学习并保持 VLM 的推理能力至关重要 - 其次,在System 1 训练阶段,作者在附加潜在查询Z 之前,从上下文序列X 中移除显式的像素目标文本
在这种情况下(w/o Pixel Goal),潜在目标特征无法关注显式的像素目标信息
这会导致性能出现明显下降,这验证了显式的像素目标不仅为扩散策略提供了有价值的指导,还提升了可解释性和泛化能力 - 最后,作者考虑了一种变体,在这种变体中,仅将像素目标文本在 VLM 最后一层的隐藏状态用作 System 1 的条件信号
这种设置(w/o Latent Goal)带来了较弱的性能。其原因是,在没有潜在目标查询的情况下,System 1 被限制为被动地消费固定的 VLM 特征,而无法学习哪些隐藏状态应当作为条件使用
这限制了从 System 2 到 System 1 的自适应信息流
第二,对于System 1 与 SOTA Point-Goal 导航策略
为了验证作者双系统联合训练框架的优势,作者移除潜在目标,并利用额外的深度信息将显式的像素目标转换为点目标(point-goal)
随后,接入最先进的 point-goal 导航策略(例如 iPlanner Yang et al. (2023) 和 NavDPCai et al. (2025)),以替换 System 1 作为局部规划器
表 4 的结果表明,即便给定 oracle深度,这种模块化流水线的表现仍不如双系统方法

作者将这一性能差距归因于两个关键因素:
- point-goal 规划器生成的轨迹分布与 System 2 训练数据中的轨迹分布存在差异,从而导致像素目标预测性能下降
- System 1 具有很强的基于视觉的避障行为,使其对沿正确方向的小幅像素目标偏移具有鲁棒性,能够保持精确且感知障碍物的轨迹,但对较大偏移或语义上错误的目标则不具备鲁棒性见图 8

相比之下,point-goal 方法通过直接将像素目标投影到世界坐标系中的一个点,对即便是很小的像素误差也极为敏感
// 待更

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 14
14 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)