InternVLA-N1——规划-执行双系统下的VLN基础模型:具备学习型的潜在规划能力,可部署在轮式、四足、双足人形上
本文介绍了InternVLA-N1双系统视觉语言导航模型,该系统通过System2(基于多模态大语言模型的像素目标规划器)进行中长期规划,System1(基于扩散的轻量级视觉导航策略)执行实时路径规划。为解决双系统同步延迟和二维像素坐标歧义问题,模型引入了异步推理机制和潜在token表征,并通过世界模型增强潜在规划能力。研究团队还开发了高效仿真数据生成流程,构建了包含5300万图像和80万指令的大
前言
实话讲,我们接的订单中,涉及到越来越多导航的内容——比如 展厅讲解,因为宇树自带的导航/避障 还有待成熟,故这一两年,大家对人形导航的研究、探索、优化从未停止过,包括我司
- 要么基于传统导航框架,比如先使用宇树G1的SDK获取传感器数据,后将数据接入通用SLAM算法(如FAST-LIO2、LIO-SAM),最后通过ROS Navigation2框架实现导航
- 要么基于试图摆脱建图的VLN
而之前博客内解读过的navila,如果编译经常会出现各种版本冲突的情况,大部分真到真机部署后,其导航成功率都不太理想,还需要不断优化
故我也一直在高度关注VLN的进展,加之我个人组建的『七月具身:VLN为代表的人形导航』群里(如想加群 一块交流者,私我你的个人简介即可),有群友提到了InternVLA-N1,故本文来解读之
据: github.com/InternRobotics/InternNav,可知
Time Update 2026/01 InternNav v0.3.0 released. 2025/12 We introduce Interactive Instance Goal Navigation (IIGN) and release VL-LN Bench to enable InternVLA-N1 to solve this task, with large-scale dialog-trajectory collection plus training and evaluation support. See our website for details. 2025/12 Training code for InternVLA-N1 and the corresponding usage doc is now available. This release provides two model configurations:
- InternVLA-N1 (Dual System) with NavDP*
详见:huggingface.co/InternRobotics/InternVLA-N1-w-NavDP- InternVLA-N1 (Dual System) DualVLN
For model architecture and training details, please refer to the DualVLN paper.2025/11 InternNav v0.2.0 released — added distributed evaluation support for VLN-PE. 2025/10 Add a inference-only demo of InternVLA-N1. 2025/10 InternVLA-N1 technical report is released. Please check our homepage. 2025/09 Real-world deployment code of InternVLA-N1 released. Upload 3D printing files for Unitree Go2. 2025/07 Hosting the 🏆 IROS 2025 Grand Challenge (see updates at official website) 2025/07 InternNav v0.1.1 released
第一部分 InternVLA-N1——双系统下的VLN基础模型,具备学习型潜在规划能力
1.1 引言与相关工作
1.1.1 引言
导航是机器人学中的一项基础任务。在实践中,导航系统通常以语言指令和视觉观测为输入,并据此执行规划出的轨迹
- 近年来,该领域取得了显著进展
从基于离散目标规划构建基准数据集的探索,比如Anderson等人(2018a)
Vision-and-Language Navigation: Interpreting Visually-Grounded Navigation Instructions in Real Environments
CVPR 2018
首次提出 R2R 基准,把自然语言指令与真实室内场景图像对应,建立离散导航图评测协议
再比如Ku等人(2020)
Room-Across-Room: Multilingual Vision-and-Language Navigation with Dense Spatiotemporal Grounding
引入 RxR 数据集,把指令扩展为多语言并给出更细粒度的时空对齐标注,推动跨语言 VLN 研究
到连续动作空间,比如Krantz等人(2020b)
Beyond the Nav-Graph: Vision-and-Language Navigation in Continuous Environments
ECCV 2020
提出 VLN-CE 设定,摒弃离散导航点,直接在连续空间里用低层控制指令完成语言引导导航
再到结合运动控制器的物理真实仿真
比如Cheng等人(2025),NavILA: Legged Robot Vision-Language-Action Model for Navigation
其利用多模态大模型为足式机器人生成连续动作,实现仿真到真实的长程导航,强调动态避障与步态协同
再比如Wang等人(2025b)
Rethinking the Embodied Gap in Vision-and-Language Navigation: A Holistic Study of Physical and Visual Disparities
系统量化物理动力学与视觉差异带来的“具身差距”,提出新基准与评估指标,推动仿真-真实迁移 - 另一方面,得益于其强大的先验知识,多模态大语言模型(multi-modalLLMs)为在仿真环境中训练此类模型并泛化到开放的真实世界提供了新的潜力
——————
研究社区对此方向表现出越来越浓厚的兴趣
比如Cheng等人(2025)——NavILA
Wei等人(2025)
StreamVLN: Streaming Vision-and-Language Navigation via Slow-Fast Context Modeling
采用慢-快双路网络在线融合历史视觉-语言上下文,支持机器人在长时导航中持续理解新指令
Zhang等人(2025a)
UniNaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
以视频 token 为统一接口,将多条导航任务(VLN、探索、目标搜索)合并到单一模型,实现零样本跨任务迁移
Zheng等人(2024)
Towards Learning a Generalist Model for Embodied Navigation,提出通用导航大模型,通过大规模预训练+提示微调,在多种机器人形态与场景上实现一次性部署
并已在多种机器人形态上进行了初步且成功的尝试,包括四足机器人和人形机器人
然而,尽管这些模型是在诸如 VLN-CEKrantz et al.(2020b) 这样的连续环境基准上开发的,它们的动作空间却被简化为离散选项,并以端到端的方式进行预测
因此,它们只能在这一受限空间中采取短期动作步,并在推理速度以及碎片化的导航行为方面表现不佳
- 直观来看,相较于从视觉观测和语言指令到直接动作输出的“硬映射”(即端到端的VLA)
一种更自然的目标类型应当是中期目标(比如规划层面的系统2),尤其是基于图像像素的中期目标,它们指示机器人应该前往何处,并且能够与多模态 LLM 的视觉落地能力对齐
- 整体框架的运行机理类似于人类认知理论,即Kahneman 2011-Thinking, fast and slow中的“系统1执行、系统2思考”
且目前也已有若干基于这一思想而构建的VLA模型,例如Helix FigureAI(2025)、GR00T(Bjorck等,2025)、HiRobot(Shi等,2025)以及OneTwoVLA(Lin等,2025b)
来自上海AI LAB的研究者提出了InternVLA-N1,这是首个引入把学习到的潜在规划(learned latent plans)作为中间表征、开放的双系统视觉-语言导航基础模型
- 其对应的paper地址为:InternVLA-N1: An Open Dual-System Vision-Language Navigation Foundation Model with Learned Latent Plans
其核心作者包括
Wenzhe Cai, Delin Feng, Yu Liu, Jiangmiao Pang, Jiaqi Peng, Chenyang Wan, Hanqing Wang, Liuyi Wang, Tai Wang, Meng Wei, Yuqiang Yang, Xiqian Yu, Chenming Zhu
以及还有几十个贡献者,详见原论文最后 - 其对应的项目地址为:internrobotics.github.io/internvla-n1.github.io
其对应的GitHub地址为:github.com/InternRobotics/InternNav
————
其GitHub上显示
[2025/09] Real-world deployment code of InternVLA-N1 is released.
其中
- 与在完全可观测环境(如桌面操作)中的规划不同,InternVLA-N1中的系统2需在部分可观测和移动外感知视角的条件下,根据语言指令进行多轮、且精确的规划
- 与此同时,系统1负责在真实世界环境中执行这些计划,并能够稳健应对诸如行人等动态干扰
接下来,分三个层面阐述,层层递进
首先,为了解决这些挑战,如下图所示
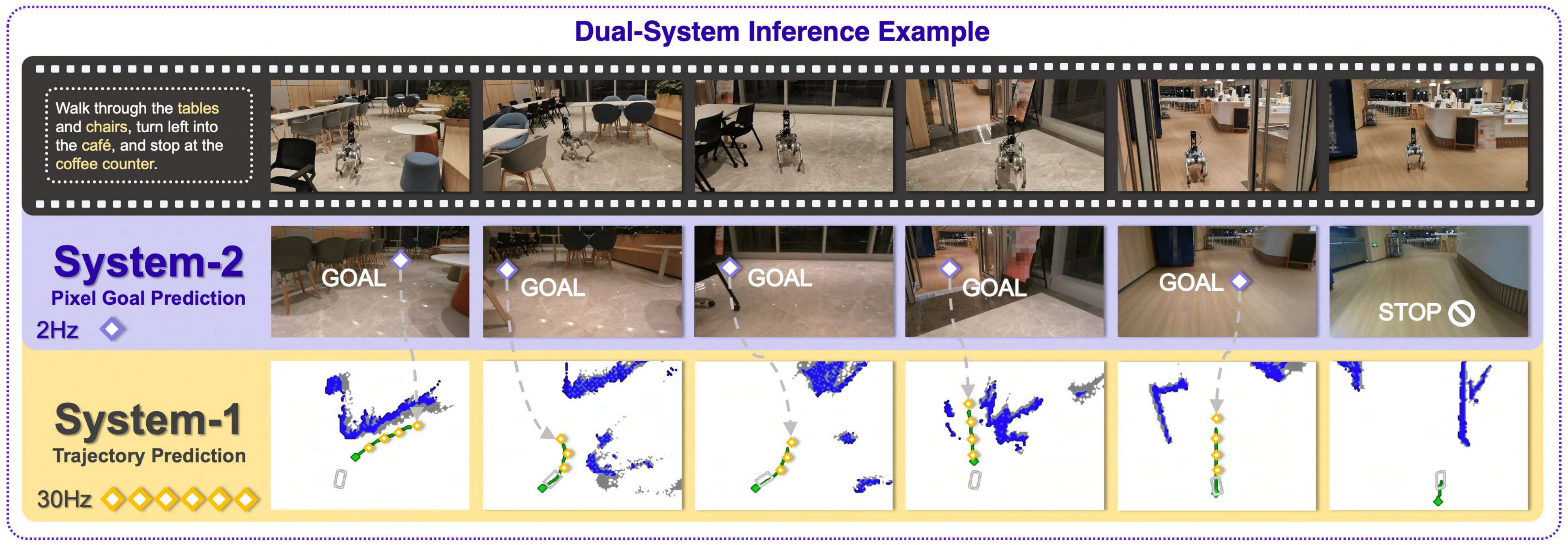
- 作者将System 2设计为像素目标规划器,利用VLM作为骨干网络,从而利用其内在的常识知识和多模态感知能力,且将像素目标定义为投影到二维图像平面上的首选导航航路点
We define the pixel goal as the preferred navigation waypoint projected on the 2D imageplane
即,System 2被训练以使其像素定位(pixel grounding)能力与视觉语言导航VLN领域对齐 - 与之相辅相成地,System 1被设计为一种轻量级、基于扩散的视觉导航策略,能够在由System 2生成的目标条件下执行实时路径规划
即,System 1被训练为在显示目标(包括像素目标坐标)的条件下,生成指向该目标的无碰撞的导航路径
然,尽管这两个系统在预训练后可以级联组成一个完整的VLN框架,但这一设计也带来了若干关键挑战
- 首先,将System 2的规划与System 1的执行同步,会显著增加整体延迟,因为System 1必须等待多模态LLM的响应
这种延迟削弱了系统实时有效响应的能力,从而降低了其在动态环境中的可行性 - 其次,使用二维像素坐标来表示导航目标会带来歧义,经常导致使System 1出现次优甚至混乱的行为
故,为了解决这些问题,作者引入了一个额外的微调阶段,该阶段支持异步推理,并增强了位于二者之间的“中间目标接口”的空间表示能力
- 具体来说,在微调过程中,System 1 持续接收最新观测信息,而 System 2 则基于延迟输入进行操作
这一设置促使 System 1 能够动态评估目标完成情况,并适应异步执行的节奏
对于这点,我第一反应想到了helix 的设计,即基于不同的采样频率
包括另一个相似工作HiRT的设计 亦如此,具体如下图左侧所示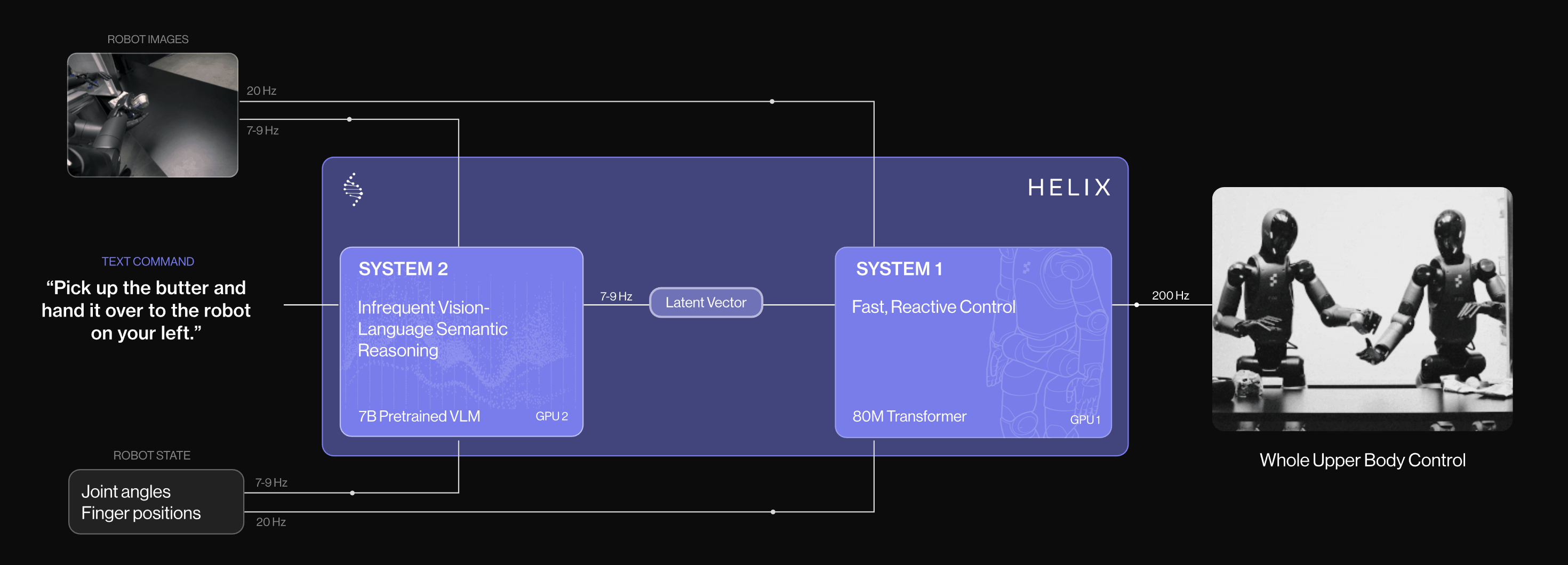
上面用于动作执行的vision encoder的采样频率偏高:为1/ 1 × step,比如1/ (1×5) = 1/5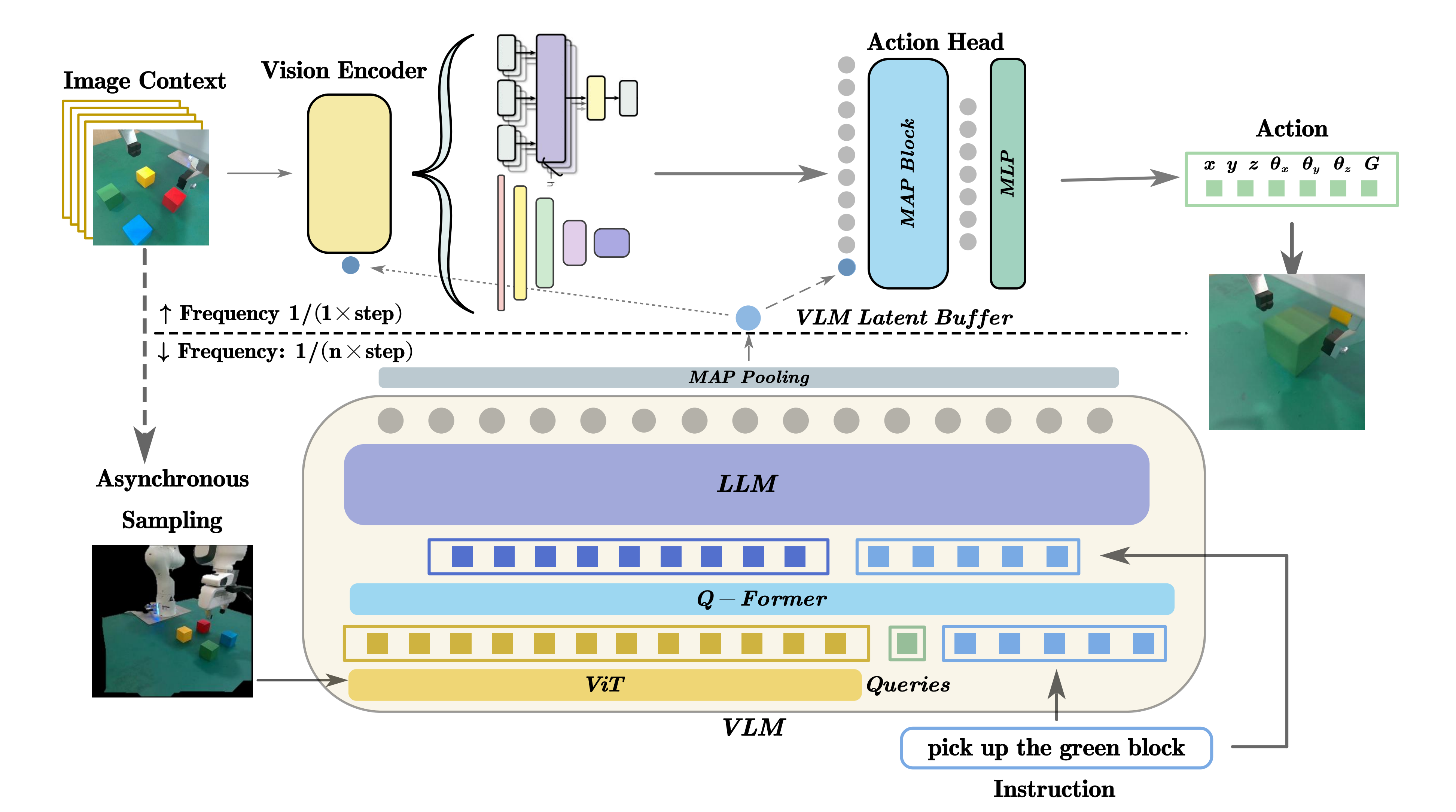
下面用于推理规划的VLM的采样频率偏低:为1/n × step 比如1/ (3 × 5) = 1/15 - 此外,作者用可学习的潜在 token 替换了显式像素目标,通过联合调优使其能够提供更具信息量的隐式规划参考
Further more, we replace explicit pixelgoals with learnable latent tokens, enabling potentially more informative implicit planning referencesthrough joint tuning.
为增强并验证这些潜在表征,作者进一步训练了一个基于潜在计划(latent plans)的世界模型,用于预测后续的自我视角观测序列
他们声称,实验表明,他们的世界模型可以围绕规划目标“生成”出一致且高质量的自我视角观测序列
视频预测目标有助于从潜在token 中提取空间信息,并加速联合调优过程的效率,同时也带来了一个可利用真实世界视频数据的可扩展训练范式
为支持上述预训练和联合微调,作者构建了一条高效的仿真数据生成流水线,能够在单机上每天生成 50K 条导航轨迹。结合自动指令标注和数据筛选流程,该流水线得以构建大规模导航数据集 InternData-N1,其中包含来自 3,000 余个室内场景的超过 5,300 万条自视角图像观测和 80 万条语言指令
1.1.2 相关工作
// 待更
1.2 InternData-N1 数据集
对于导航任务,大多数真实世界数据集(Hirose 等,2018,2023;Karnan 等,2022;Shah 等,2021)受限于场景多样性和规模
同时,互联网视频数据集(Lin 等,2023;Liu 等,2025)则存在定位和建图信息不精确的问题,从而限制了其作为轨迹预测导航数据集的可靠性和可行性
相比之下,作者提出了三条高效的数据生成流水线,用于在仿真环境中构建导航数据集,旨在支持可扩展的训练
具体而言,InternData-N1数据集由子集 VLN-N1、VLN-CE 和 VLN-PE 组成,它们具有互补的特性:
- VLN-N1 是从大规模开源 3D 资产中收集而来,并通过大量的领域随机化来增强对多样化真实世界场景的泛化能力
- VLN-CE 提供高质量、细粒度的指令标注,从而提升在长时程下游导航任务中的性能
- VLN-PE 在基于物理的仿真中集成了低层运动控制器,通过在导航过程中对逼真的机器人动力学进行建模,从而支持高效的仿真到现实sim-to-real迁移
1.2.1 VLN-N1
丰富的开源场景资产为生成室内导航轨迹提供了理想的实验平台。作者采用了Replica(Straub等, 2019)、Matterport3D(Chang等, 2017)、Gibson(Xia等,2018)、3D-Front(Fu等, 2021)、HSSD(Khanna等, 2024)以及HM3D(Ramakrishnan等, 2021)作为场景库
为了生成具身视角ego centric的真实导航过程,作者采用多阶段路径规划流程生成一批无碰撞且平滑的轨迹
首先,基于网格结构为每一层楼构建欧几里得符号距离场(ESDF),然后全局路径规划包含三个步骤——这点 与以往工作(Cai等, 2025)类似:
- 利用A*算法为随机采样的起点和目标初始化全局路径
- 利用 ESDF 地图对轨迹关键点进行优化
- 对轨迹进行平滑
收集到的轨迹被用于在 BlenderProcDenninger et al.(2020) 中渲染 RGB 和深度观测
为同时生成细粒度和长时程任务的语言指令,作者
- 首先基于轨迹的几何信息提取关键帧,例如在发生急转弯时对应的帧。根据提取出的关键帧,作者将整条轨迹划分为若干子片段
- 随后,采用开源多模态大模型 LLaVa-OneVision Li et al.(2024),为每个子片段生成细粒度语言指令
作者发现其生成指令的语言风格较为单一,因此进一步引入另一种语言模型 Qwen3-72b,对每个片段的语言指令进行改写,并将所有子片段的指令汇总为一条用于长时程任务的整体指令
具体而言,按照如图 3 所示的流程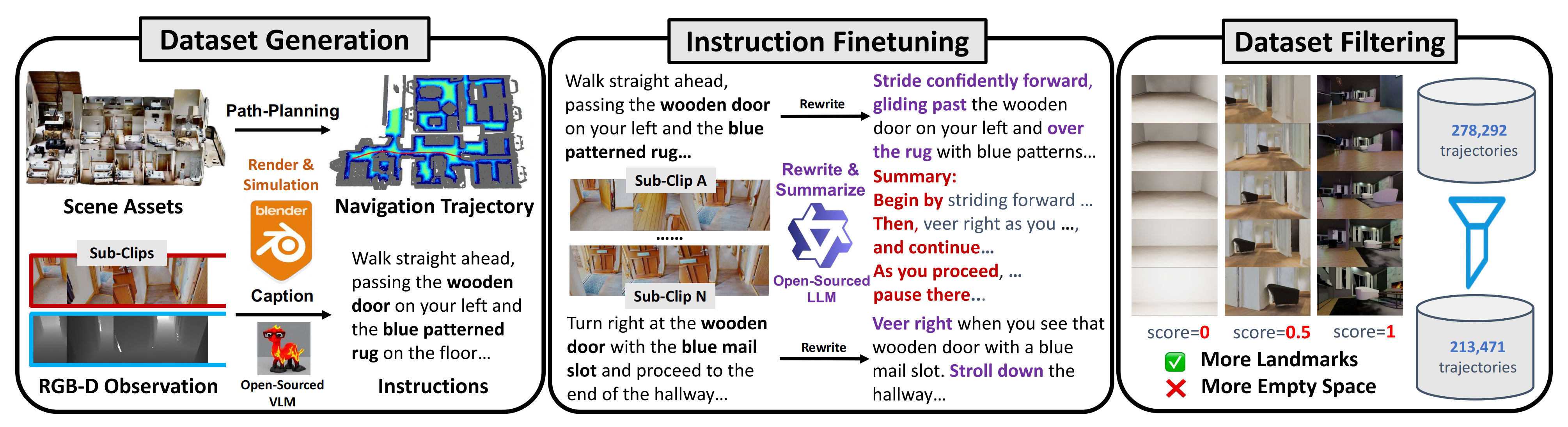
————
最终,作者构建了一个新的大规模导航数据集 VLN-N1
至于数据集的比例细节及统计指标如图 2 所示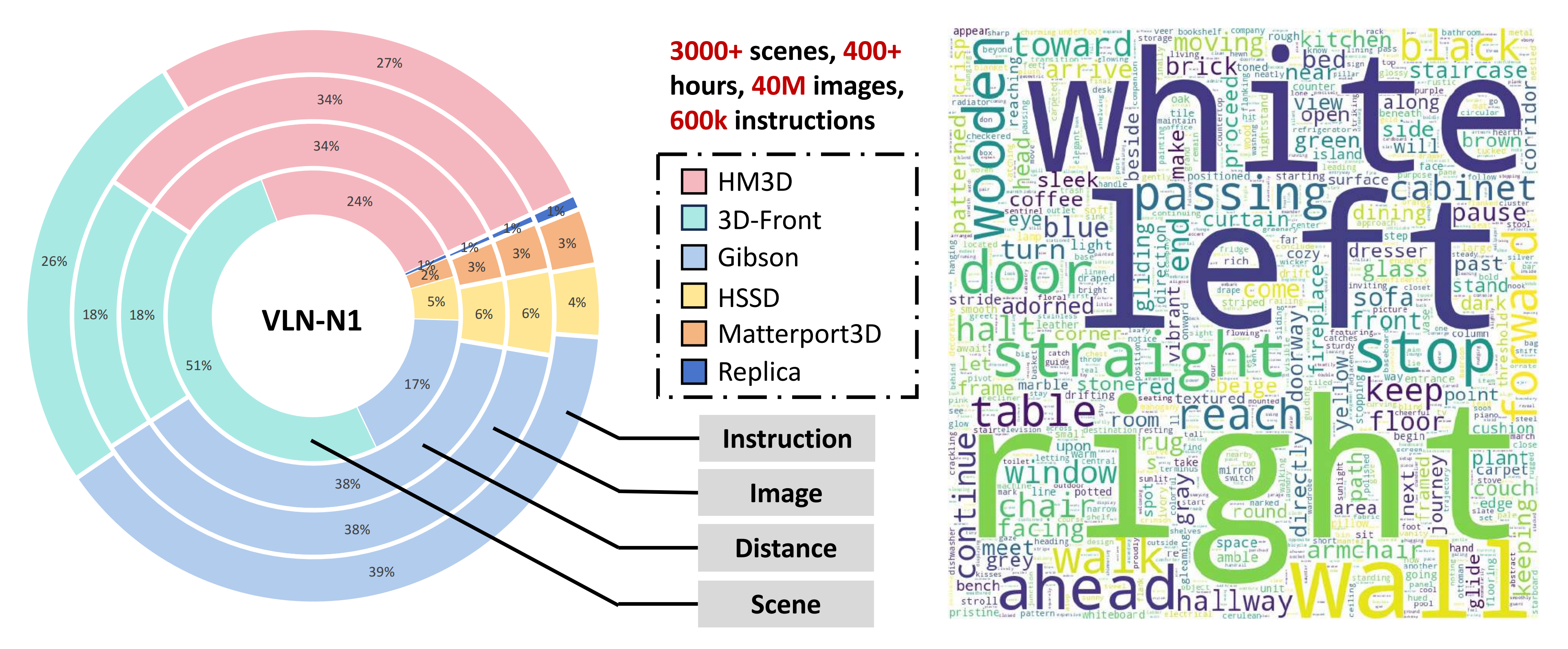
1.2.2 VLN-CE
VLN-CE数据集源自已有的视觉与语言导航基准,包括VLN-CE(Krantz等,2020b)、EnvDrop(Tan等,2019)和ScaleVLN(Wang等,2023a),这些基准旨在训练通用的室内导航模型
- 且作者利用Habitat模拟器(Szot等,2021),渲染Matterport3D(Chang等,2017)和HM3D(Ramakrishnan等,2021)中的场景,并回放相应的导航片段以收集数据集
具体而言,作者使用Habitat 内置的 ShortestPathFollower agent,沿预定义的参考路径生成轨迹,每条路径都对应一条对齐的细粒度自然语言指令 - 动作空间遵循Habitat默认的VLN任务配置,包括四个离散动作:
MOVE_FORWARD(前进0.25米)
TURN_LEFT(左转15°)
TURN_RIGHT(右转15°)
STOP(停止)
在每个导航片段中,作者记录了RGB观测与相应的动作序列
最终,作者共采集了332,179个导航片段,覆盖Matterport3D和HM3D数据集中的856个独特场景。为便于训练System 2,作者将原始轨迹划分为多个片段,并将代理的位置投影到二维图像平面上,作为像素级目标标签
最终,作者共收集了 332,179 个 episode,覆盖 Matterport3D 和 HM3D 两个数据集中的 856个独特场景。为使该数据集可用于训练 System 2,作者将原始轨迹切分为多个 clip,并将智能体的位置投影到二维图像平面上,作为像素级目标标签。更多细节见第 4.2 节
1.2.3 VLN-PE
VLN-PE 数据集旨在通过在物理仿真平台 InternUtopiaWang et al.(2024a) 中采集反映真实机器人运动的数据,以缩小视觉语言导航(Vision-and-Language Navigation, VLN)任务中的从模拟到现实sim-to-real鸿沟
- 与之前的 VLN-N1 和 VLN-CE 不同,VLN-PE明确地将机器人具身性与运动策略纳入数据采集流程
作者采用多样化的机器人平台,包括四足机器人(Unitree AlienGo)、人形机器人(Unitree H1 和 G1)以及轮式机器人(Jetbot),并利用现有的基于学习的运动控制器(Long 等人, 2024a,b;Pan 等人,2025)来控制其移动 - 每个机器人都被要求根据一条与自然语言指令对齐的预定义导航路径进行移动,从而生成对应的自我视角观测数据
语言指令和路径主要来源于 R2R 数据集 Anderson et al.(2018a),并在此基础上进行了修改
且作者剔除了涉及楼梯通行(即上下楼梯)的片段,因为当前的运动策略尚无法稳定应对这类场景
最终得到的 VLN-PE 数据集覆盖了 Matterport3D 数据集(Chang 等人, 2017)中的 61 个场景,共包含 8,679个片段
1.3 InternVLA-N1的完整方法论
1.3.0 概述
如图4所示,InternVLA-N1 采用了一种由多个组件构成的架构,具备双系统设计,协同融合了高层指令解析与低层动作执行
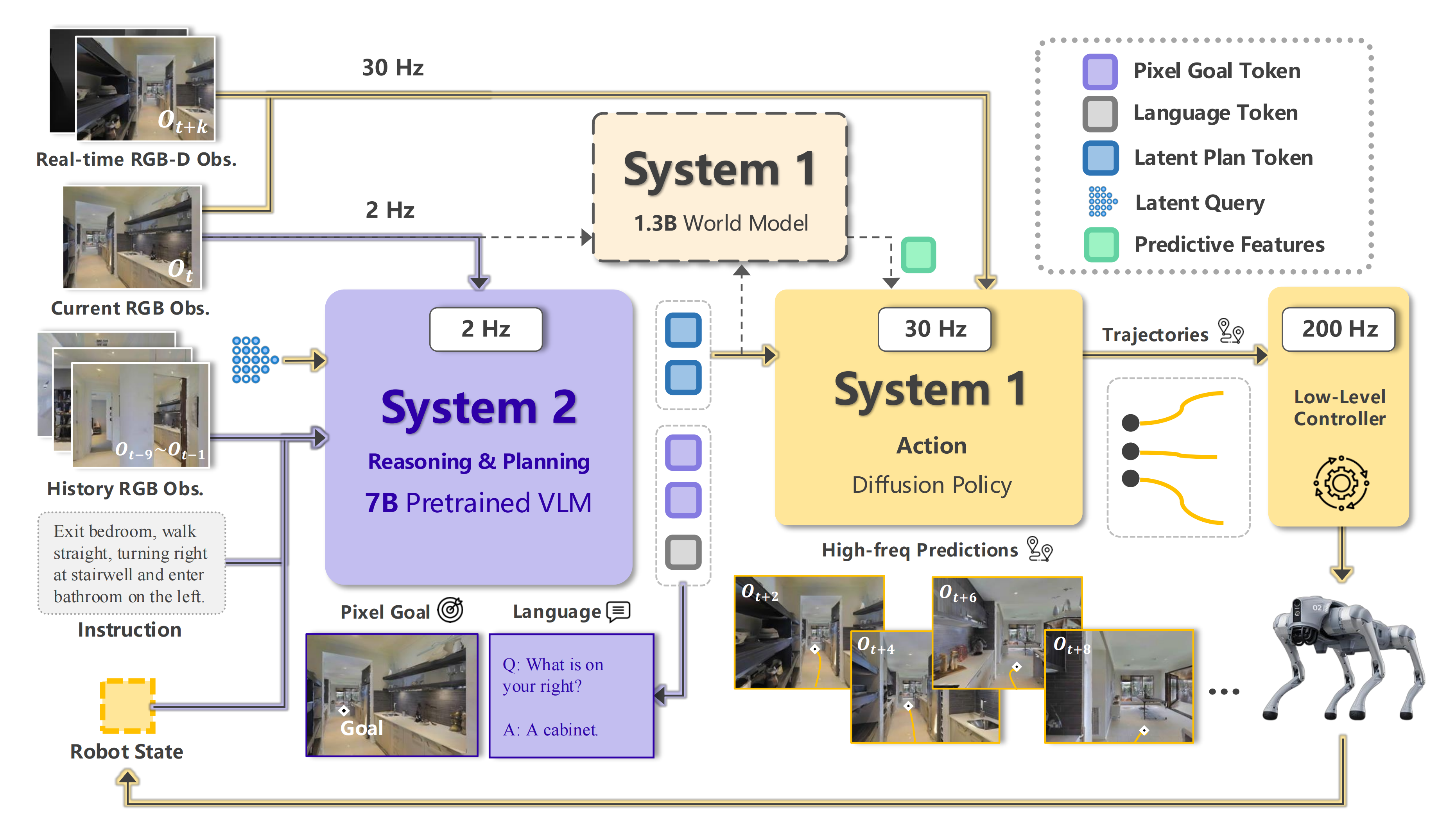
简言之
- System 2感知长时域多模态输入,并以2 Hz的频率将其转换为中期潜在计划(相当于helix中的Latent Vector,属于被压缩后的潜在语义信息)
- 而System 1则处理异步的潜在计划以及短期视觉观测,从而实现实时决策
『System 2 perceives the long-horizon multi-modalinputs and translate into mid-term latent plans at 2 Hz, while System 1 processes the asynchronous latent plans along with short-term visual observations to enable real-time decision making』
具体而言,该系统集成了:
- 系统2:一个基于视觉-语言模型VLM的规划模块,该模块通过依托图像的推理来解释导航指令,从而预测中程路标目标(mid-term waypoint goals)
————
通过在图像空间中预测像素坐标,它有效地将指令理解与空间推理连接起来,从而实现对长时程导航指令的跟随 - 系统1:一个多模态、以目标为条件的扩散策略,由潜在计划引导或由显式目标支撑,能够在当前观测以及来自 System 2 的异步潜在特征(asynchronous latent features)的条件下,生成可执行的短时域轨迹,从而在复杂环境中实现鲁棒的实时控制和局部决策
总之,为了充分释放双系统架构在开放世界泛化和异步推理能力方面的潜力,作者设计了一套课程训练方案
- 首先,在同步环境中,分别对每个系统进行独立训练,使其利用显式目标学习基本的导航技能
- 随后,引入联合微调阶段
在该阶段,作者将可学习的token 作为隐式中期目标(implicit midterm goals)融入System 2,以减少基于像素目标的所带来的不确定性
此外,System 2还接收延迟观测,这迫使System 1适应异步执行
1.3.1 System 2:基于Qwen-VL-2.5的像素定位规划
系统的目标规划模块基于 Qwen-VL-2.5 构建,该模型是一款强大的开源视觉-语言模型,具备空间定位能力
Qwen-VL-2.5 主要包括三个核心组件:视觉编码器、语言模型,以及用于模态融合的轻量级多模态连接器
该模型通过在响应空间查询时直接预测像素坐标来支持 grounding 任务,因此特别适合需要精细定位的任务,例如指代表达理解和视觉问答
- 为了使 Qwen-VL-2.5 能够适应视觉与语言导航(VLN)任务,作者将高层次规划表述为最远像素目标预测问题
模型的输入为一序列自视角图像以及对应的语言指令,输出为图像中的一个二维坐标,该坐标对应于下一步首选的导航路标点 - 且作者使用 InternData-N1 的 VLN-CE 子集对 Qwen-VL-2.5 进行了微调
通过度量智能体位置与相机视野之间的可见性,作者将每条原始的 VLN-CE 轨迹划分为多个最远像素预测训练样本,最终为导航规划任务生成了超过500万个样本
此外,System 2 负责在任务完成时决定何时停止,并在图像中未检测到合适的导航航路点时执行原地旋转。与直接动作预测相比,作者的方法为将多模态理解与空间决策相衔接提供了一种更高效的机制
1.3.2 System 1:多目标条件扩散策略
他们的系统1模型是一种基于扩散模型的局部导航策略,旨在实现实时避碰和路径规划。其采用的架构与作者先前的工作 NavDP Cai et al(2025)类似,该工作能够同时预测导航轨迹及其相应的安全评分,以用于轨迹筛选
且为了提升在不同类型目标上的导航性能,作者引入了显式的目标嵌入对齐作为额外的训练目标
- 具体而言,作者将 点目标point-goal 视为一种通用且无歧义的目标表示形式
且系统中引入了两个辅助预测头,分别以 图像目标image-goal 和 像素目标pixel-goal 的嵌入作为输入,并以 点目标point-goal 作为监督标签
————
goal alignment 损失与 action 损失和 critic 损失共同构成整体训练目标 - 通过引入goal alignment 目标,各类导航任务都被隐式地转化为point-goal 导航任务,从而显著降低了学习复杂度
另,System 1 在 VLN-N1 子集上进行训练
1.3.3 分层联合训练
1.3.3.1 阶段一:单系统预训练
System2 的训练过程从一个已经在大规模图文语料上预训练过的视觉-语言模型(Qwen-VL-2.5 7B 模型)开始。作者通过任务自适应的有监督微调,将该模型适配于面向导航的规划
- 具体而言,作者使用包含导航指令、第一人称视角观测以及中期航路点组成的成对轨迹(use paired trajectories consisting of navigation instructions, egocentric observations, and mid-termway points)
在该设置中,每个中期航路点被表示为当前观测图像像素空间中的二维坐标 - 在训练过程中,所有组件——包括视觉编码器、跨模态连接器和语言模型,都会在作者精心整理的 SFT 数据集上进行一个 epoch 的联合优化
模型学习在上下文中理解指令,并在图像上预测与目标导航航路点相对应的像素级目标位置
『The model learns to interpret the instruction in context and predict the pixel-level goallocation on the image that aligns with the intended navigation waypoint』
除了DepthAnything Yang 等人提出的RGB 编码器外,System 1 模型的所有组件均从头开始训练。System 1 模型的训练包含三个主要目标:
- 不同目标之间的嵌入对齐
对于嵌入对齐,作者增加了两个辅助的点目标预测任务,输入分别为图像目标编码或像素目标编码。这有助于从零开始训练的目标编码器捕捉到对导航任务重要的表征
具体而言,设
图像目标为,当前RGB 观测为
像素目标为
点目标为
为了编码像素目标,作者
,其中仅
附近的局部区域为1,其余像素为0
,和图像掩码 + 观测(
编码后的嵌入和
之后再接一个额外的MLP 层,用于预测估计的点目标
因此,目标对齐损失可以表示为: - 扩散策略的噪声预测
- 评论家预测
当然,上面后面两点所示的「扩散过程和评论家预测的训练损失」均遵循NavDP 中提出的方法
作者联合优化动作损失、评论家损失和目标对齐损失,并使用加权系数对它们进行平衡。作者将系数设置为α = 0.8, β = 0.2 和γ = 0.5
整体训练目标定义为:
1.3.3.2 阶段二:多系统联合微调
用一个2-D 像素来表示精确的3-D 导航目标是含糊不清的,并且在嵌入式设备上为一个7B VLM 执行高速推理也具有挑战性。因此,能够桥接不同系统的中间特征连接设计(the design of the intermediate feature connections)是一个关键因素
- 这些中间特征应当在不降低原有系统效率或表征能力的前提下,保留其优势,同时又能够在具有互补功能的这些系统之间实现有效的信息流动
- 且作者没有直接使用VLM 的隐藏状态,因为其中包含大量异构信息,而是引入了一组可学习的潜在查询(latent queries)
输出的潜在特征作为紧凑的中间表示,通过提示微调将视觉语言模型(VLM)与扩散策略模型连接起来
此外,作者调整两个系统输入的时间对齐以适应异步执行。具体而言,System 1 在时间步 , 接收最新观测,而System 2 的RGB 记忆输入则从范围
内较早的时间步中采样,其中
是从范围(0,12) 中随机选取的间隔。这种时间解耦使双系统框架能够更好地适应异步执行
1.3.4 扩展:通过世界模型学习更优的潜在计划
- 为了构建更优的潜在计划表征,作者提出了一种模型扩展方法,即利用预测型世界模型解码器生成朝向中期目标的自我中心观测序列
这种范式有望借助互联网视频实现可扩展的训练,并隐式地增强在动态环境中的预测能力 - 具体而言,作者采用了预训练的1.3B Wan2.1模型(Wan等,2025)作为骨干网络,且用系统 2 生成的潜在规划token替换了其原有的基于 T5 的编码器
Specifically, we adopt the pre-trained 1.3B Wan2.1model Wan et al. (2025) as our backbone, replacing its original T5-based encoder Raffel et al. (2020)with latent plan tokens generated by System 2
经过在 InternData-N1 导航数据集上的微调之后,该世界模型能够在给定 System 2 输出的潜在规划(latent plans)的条件下,高精度地模拟未来结果
第二部分 实验
2.1 System2 评估
2.1.1 数据集与评估指标
作者在R2R-CE(Anderson等,2018a)和RxR-CE(Ku等,2020)基准上对System 2进行了评估,这两项基准均在VLN-CE(Krantz等,2020b)设定下,使用Habitat模拟器进行实验。这些基准测试在Matterport3D环境中模拟了逼真的室内导航场景,要求智能体在连续控制下遵循自然语言指令
- R2R-CE仅提供英文指令,路径相对较短;
- 而RxR-CE则是一个大规模多语言基准,路径更长且更加多样化
为了评估System 2的泛化能力,作者在两个基准测试的验证集未见分割上进行了所有实验。按照以往的研究,作者采用了标准的VLN评估指标:
- 导航误差(NE),用于衡量到达目标的最终距离;
- 成功率(SR),即智能体在距离目标3米范围内停止的回合比例;
- Oracle成功率(OSR),即路径上最佳点被视为成功;
- 以及按路径长度加权的成功率(SPL),该指标对不必要的冗长路径进行惩罚
这些指标能够全面评估指令遵循过程中的有效性与效率
2.1.1 主要结果
作者将他们的方法与三大类VLN基线进行了比较:
- 利用全景图像、里程计和深度信息的传感器丰富型基线(例如,HPN+DN、CMA、GridMM、ETPNav);
- 依赖深度和单目第一视角RGB,但未利用大规模视觉-语言模型的VLN方法(如CM2、LAW、WS-MGMap);
- 基于Video-LLMs的VLN模型,仅输入单通道RGB(如NaVid、MapNav、NaVILA、UniNaVid)
InternVLA-N1在两种设置下进行了评估:仅RGB(S2)和RGB+深度(S1+S2)
如表2所示
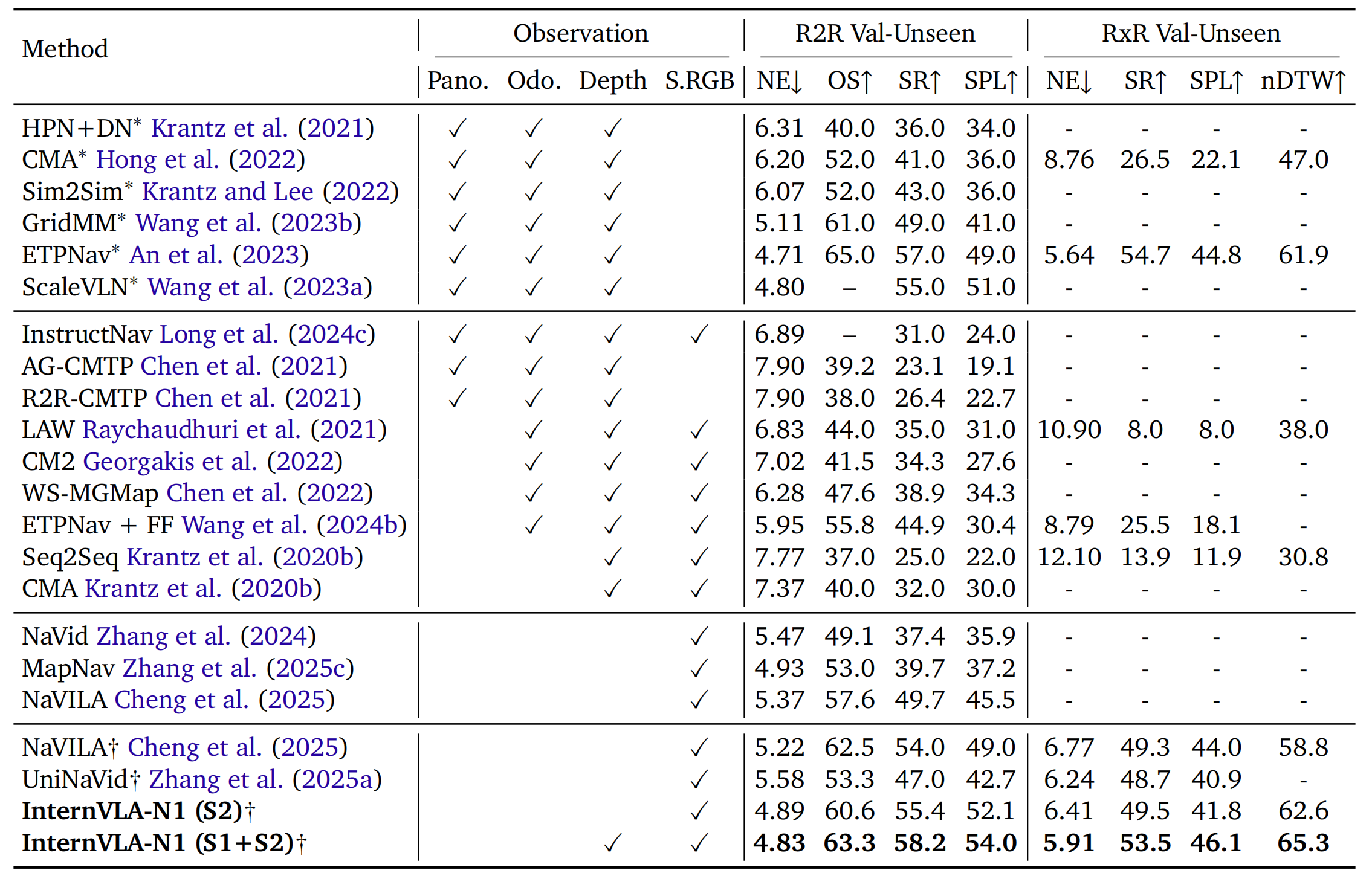
InternVLA-N1的仅RGB版本已超越所有先前基于RGB的方法
- 在R2R Val-Unseen上实现了55.4%的成功率(SR)和52.1%的SPL
- 超过了
NaVILA(SR: 54.0%,SPL: 49.0%)
和MapNav(SR: 39.7%,SPL: 37.2%)
2.2 System1 评估
2.2.1 数据集与评估指标
为评估 System 1 的泛化能力和鲁棒性,作者利用 IsaacSim 构建了一个仿真基准测试,旨在反映真实机器人部署时可能出现的仿真到现实差距
作者收集了多样化的场景,以实现全面评估。这些场景主要分为两大类:
- 一类是随机生成的布局,包含杂乱的障碍物
- 另一类是专业设计的布局,涵盖住宅和商业环境(Wang 等,2024a)
评估场景的概览如图 5 所示——用于System 1评估的ClutteredEnv和InternScenes场景概览。顶部几行为ClutterEnv,底部行为InternScenes-Home

作者将所有评估环境划分为四个子集,分别为
- ClutterEnv-Easy(10 个)
- ClutterEnv-Hard(10 个)
- InternScenes-Home(20 个)
- InternScenes-Commercial(20 个)
括号内数字表示评估场景资源的数量
在这些环境中,作者在轮式机器人上评估三种类型的局部导航任务
- 对于无目标探索任务,作者采用Episode Time 和 Explore Area 两项指标,评估碰撞规避与探索能力
- 对于点目标导航和图像目标导航任务,作者评估 Success Rate(SR)和 Success weighted by PathLength(SPL)
当智能体在距离目标点 1.0 米内到达时,判定该回合为成功。每项任务中,机器人均随机初始化,并在每个场景下进行 100 个回合的评估
2.2.2 主要结果
作者将System 1模型与多种基线方法进行了比较
这些基线方法包括
- 用于图像目标和无目标任务的 GNM(Shah 等人,2023a)、ViNT(Shah 等人,2023b)和 NoMad(Sridhar 等人,2024)
- 以及用于点目标导航任务的 DD-PPO(Wijmans 等人,2019)、iPlanner(Yang11 等人,2023)和 ViPlanner(Roth 等人,2024)
主要结果分别展示在原论文中的图 6、图 7 和图 8 中
作者发现,System 1 具备多项独特能力,使其在性能上大幅超越基线方法
具体包括:
- 在分布外场景下具备强大的避碰能力:尽管训练数据主要采集自室内场景,但在 ClutterEnv 场景下的无目标探索任务中,其表现比 NoMad 高出 2.7 倍
- 高效且一致的路径规划能力:在 InternScenes 复杂室内布局场景中,System 1 模型能够优异地推断不同区域间的连通性,成功率比以往方法高出 10.9%
- 基于图像的探索:大多数先前的本地导航方法在目标图像距离较远时难以实现图像目标导航,而InternVLA-N1能够自适应地在探索与利用之间取得平衡,性能比以往方法提升 27.1%
// 待更

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 27
27 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)