DeepSeek-R1-Zero横空出世:纯强化学习训练,推理能力对标OpenAI o1
**导语**:无需监督微调(SFT),直接通过大规模强化学习(RL)训练的大语言模型DeepSeek-R1-Zero正式开源。这款6710亿参数的混合专家模型(MoE)不仅在数学、代码等推理任务上对标OpenAI o1正式版,更通过蒸馏技术将能力压缩至32B小模型,为行业带来推理范式新突破。## 行业现状:推理能力成AI竞争新焦点2025年,大语言模型正从"对话交互"向"复杂推理"加速演进...
DeepSeek-R1-Zero横空出世:纯强化学习训练,推理能力对标OpenAI o1
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-Zero
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-R1-Zero 导语:无需监督微调(SFT),直接通过大规模强化学习(RL)训练的大语言模型DeepSeek-R1-Zero正式开源。这款6710亿参数的混合专家模型(MoE)不仅在数学、代码等推理任务上对标OpenAI o1正式版,更通过蒸馏技术将能力压缩至32B小模型,为行业带来推理范式新突破。
行业现状:推理能力成AI竞争新焦点
2025年,大语言模型正从"对话交互"向"复杂推理"加速演进。OpenAI通过o系列模型开创"测试时计算"路径,而DeepSeek则另辟蹊径——完全摒弃SFT阶段,仅通过强化学习就让模型自发涌现出思维链(CoT)、自我验证等高级推理行为。据DeepSeek官方公告显示,这种"无SFT强化学习"技术已被证实可独立激发LLM的推理能力,为解决数据枯竭时代的模型进化难题提供了全新思路。
行业数据显示,推理能力已成为企业选择AI工具的核心指标。在金融风控、科学计算等领域,具备复杂推理能力的模型能将决策效率提升3-5倍。而DeepSeek-R1系列的开源,首次让学术界和企业界能直接研究这种前沿推理机制。
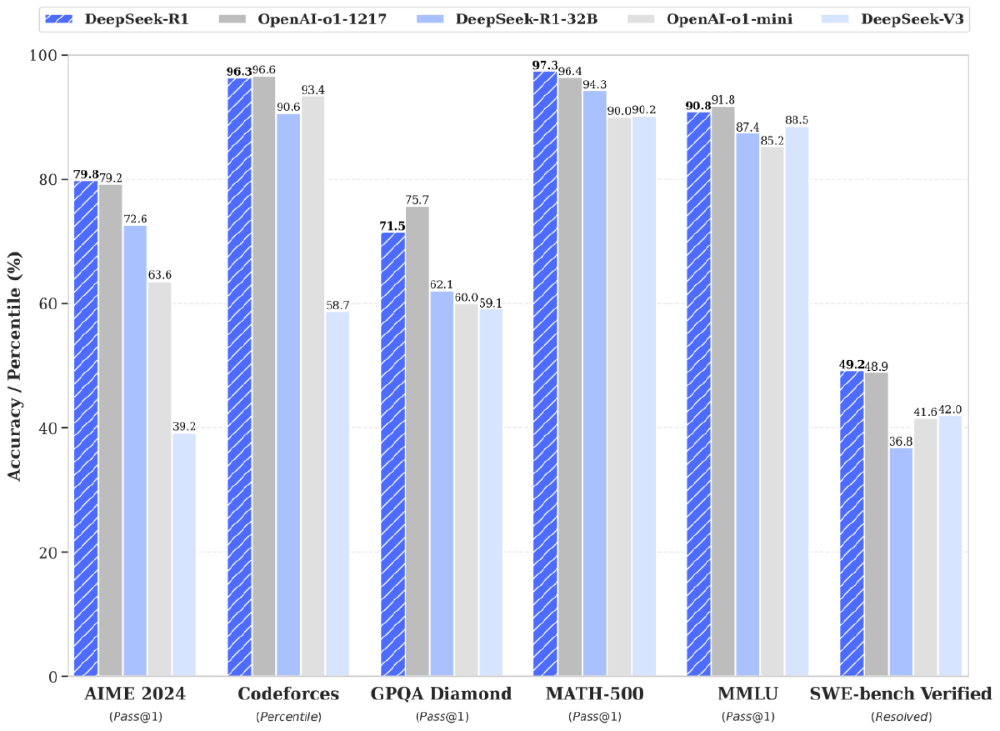
如上图所示,DeepSeek-R1在MMLU-Pro(84.0%)、DROP(92.2%)等推理基准上超越GPT-4o和Claude-3.5-Sonnet,尤其在代码领域的LiveCodeBench任务上达到65.9%的Pass@1率,显著领先OpenAI o1-1217版本(63.4%)。这一对比充分体现了纯强化学习路径在推理任务上的竞争力,为开发者选择推理模型提供了关键参考。
核心亮点:三大技术突破重构推理范式
1. 无SFT强化学习:让模型自学推理
DeepSeek-R1-Zero最革命性的突破在于跳过传统SFT阶段,直接在基础模型上应用强化学习。这种训练方式使模型通过环境反馈自主探索解题路径,自然形成了长达32,768 tokens的推理链、多步骤验证等复杂行为。官方技术报告指出,这是业界首次实证"无需人工标注推理样本也能培养LLM推理能力",为数据高效型模型训练开辟了新方向。
2. 蒸馏技术:小模型也有大能力
为解决大模型部署成本问题,DeepSeek推出基于Qwen和Llama系列的6款蒸馏模型。其中32B参数的DeepSeek-R1-Distill-Qwen-32B表现尤为突出,在AIME数学竞赛(72.6%)、GPQA钻石级问题(62.1%)等任务上全面超越OpenAI o1-mini,甚至逼近原版R1性能的85%。通过vLLM或SGLang部署,这些小模型可在单张GPU上实现毫秒级推理响应。

从图中可以看出,DeepSeek-R1-Distill-Qwen-32B在MATH-500(94.3%)和CodeForces评级(1691分)等关键指标上已显著超越GPT-4o和Claude-3.5-Sonnet。这一突破证明通过高质量蒸馏,中小模型完全能胜任专业领域推理任务,大幅降低了企业级应用的技术门槛。
3. 宽松开源协议:赋能全行业创新
DeepSeek此次采用MIT许可证彻底开放模型权重,允许无限制商用和二次蒸馏。用户协议明确支持"使用模型输出训练其他模型",这与部分厂商限制蒸馏的做法形成鲜明对比。开发者可通过以下命令快速部署32B蒸馏模型:
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768
行业影响:加速推理技术普及化
科研领域:推理机制研究新工具
开源的R1-Zero为学术界提供了罕见的"纯RL推理模型"研究对象。其展现的"自我纠错"、"多路径探索"等原生推理行为,有望帮助科学家解开LLM推理能力形成的黑箱机制。MIT License允许研究者自由修改模型结构,这将加速推理技术的迭代创新。
产业落地:垂直领域推理成本骤降
金融、科研等领域已出现应用案例。南京银行基于R1模型开发的客户经理助手,将企业信息检索整理时间从1天压缩至10分钟;安恒信息集成R1的安全智能体,在钓鱼邮件识别准确率上达到92.8%。这些案例验证了R1系列在专业场景的实用价值。
结论与前瞻:推理即服务时代来临
DeepSeek-R1系列的推出标志着大语言模型正式进入**"推理即服务"**阶段。其技术突破带来三重启示:
- 训练范式革新:纯RL路径为数据稀缺场景提供新解法
- 部署成本优化:32B蒸馏模型实现"性能-效率"平衡
- 开源生态建设:宽松协议加速推理技术普惠化
随着R1技术的普及,预计2025年下半年将出现一波推理型AI应用爆发。开发者可重点关注数学推理、代码生成等优势场景,通过官方API(输入token低至0.004元/千token)快速验证业务价值。未来,随着多模态推理、实时决策等能力的加入,R1系列有望成为通用智能的重要基石。

立足具身智能前沿赛道,致力于搭建全球化、开源化、全栈式技术交流与实践共创平台。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)